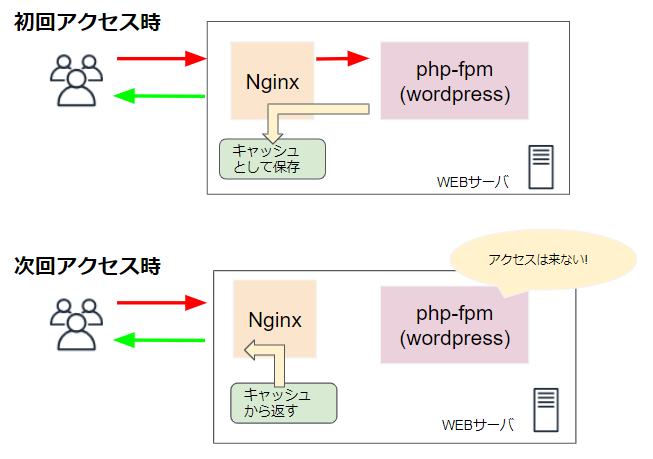
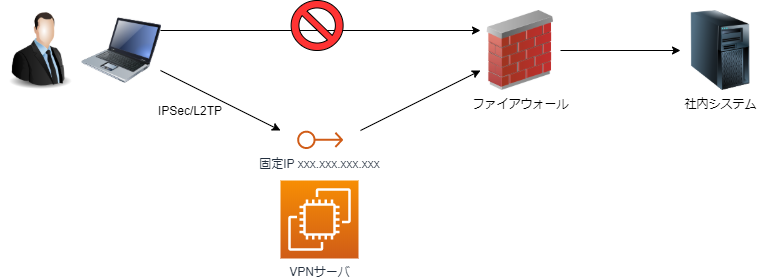
WordPressを爆速にするnginxのproxyキャッシュを冗長化しても共通で利用できるようにするアーキテクチャ(OpenResty+Redis)のご紹介2020/04/13# AWS# インフラ# WordPress# Linux
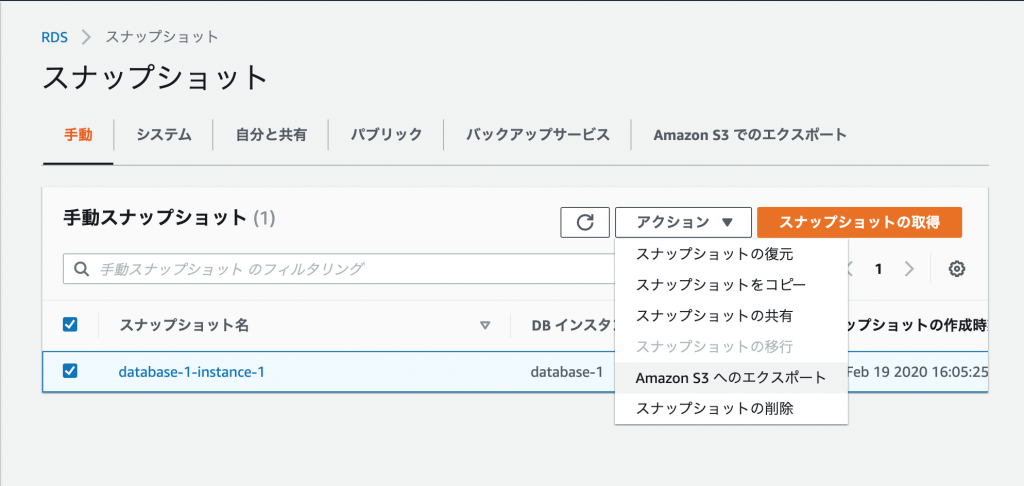
Amazon Relational Database Service (Amazon RDS)スナップショットを Amazon Simple Storage Service (Amazon S3)のエクスポートを試してみた2020/02/27# AWS# インフラ