
![Cover Image for Slack と Knowledge Bases for Amazon Bedrock で「社内ナレッジ AI ChatBot」はじめました。[RAG]](https://www.seeds-std.co.jp/blog/images/pr/f42124f0-c915-4dc3-a908-77ced7fa2ad3/thumbnail)
こんにちは。システム開発事業部のタナカです。
楽しんでますか?AIライフ。
今回は「社内ナレッジ AI ChatBot(RAG)」の運用をはじめたのでご紹介します。
はじめに
先日開催された AWS re:Invent 2023 にて、Amazon Bedrock で検索拡張生成(RAG)が簡単に実現できる、Knowledge Bases 機能が一般公開されたとアナウンスされました。
詳細は現地ラスベガスにて参加した弊社エンジニアがブログにしてくれていますが、今回は、これを社内ナレッジ専用の AI ChatBot として活用することにしました!という内容になります。

RAGとは

RAG(Retrieval Augmented Generation)とは、外部データソースから取得した情報を用いて、生成AIモデルの精度と信頼性を向上させようとするアプローチです。
情報検索とテキスト生成を統合することで、生成モデルによる応答の質と精度を大幅に向上させることができるようになりました。
具体的には、まず大規模言語モデル(LLM)に入力された指示に基づいて、外部データソースから関連する情報を検索します。次に、検索結果を LLM の生成プロセスに組み込み、LLM がより正確で信頼性の高い回答を生成できるようにするというプロセスになります。
RAGのメリット

高い精度
検索機能を組み込んでいるため、外部データソースから最新の情報や専門的なデータを取得することができ、高い精度の回答を生成することができます。
これにより、従来のモデルでは難しかった最新のニュースや特定の専門分野に関する質問に対しても、正確な情報を提供することが可能になります。
柔軟性と適応性
様々な種類の外部データソースにアクセスし、それらを利用して回答を生成するため、異なるコンテキストや要求に柔軟に対応することができます。
これにより、より幅広いトピックや質問に適応し、多様なユーザーニーズに応えることができるようになります。
知識の拡張
生成モデルの知識ベースを外部データソースによって拡張することになるので、より豊富な知識を活用して回答を生成することができます。
特に、時間の経過によって変化する情報や、新しい研究成果などに対しても、常に最新の情報を取り入れることが可能になります。
LLM のことを調べているとよく出てくるこの2つのキーワード。
生成AIモデルの精度を向上させるためのアプローチという点ではどちらも同じですが、 LLM 自体への変更がなく比較的低コストでの導入が可能な「RAG」と、直接 LLM に追加学習を行うため RAG に比べて導入コストがかかる「ファインチューニング」という違いがあります。
Knowledge Bases for Amazon Bedrock

この RAG をフルマネージドで簡単に利用できるようにしたのが、Amazon Bedrock の ナレッジベースというサービスです。
ナレッジベースが LLM のために必要なベクトル変換なども含めた RAG ワークフローを管理してくれるので、ユーザーは、外部データソースとして学習させたいデータをストレージ(Amazon S3)にアップロードするだけで利用することができます。
・プレーンテキスト (.txt)
・マークダウン (.md)
・HyperText マークアップ言語 (.html)
・Microsoft Word ドキュメント (.doc/.docx)
・カンマで区切られた値 (.csv)
・Microsoft Excel スプレッドシート (.xls/.xlsx)
・ポータブルドキュメントフォーマット (.pdf)
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/knowledge-base-setup.html
ナレッジベースのプロセス概要
データの前処理
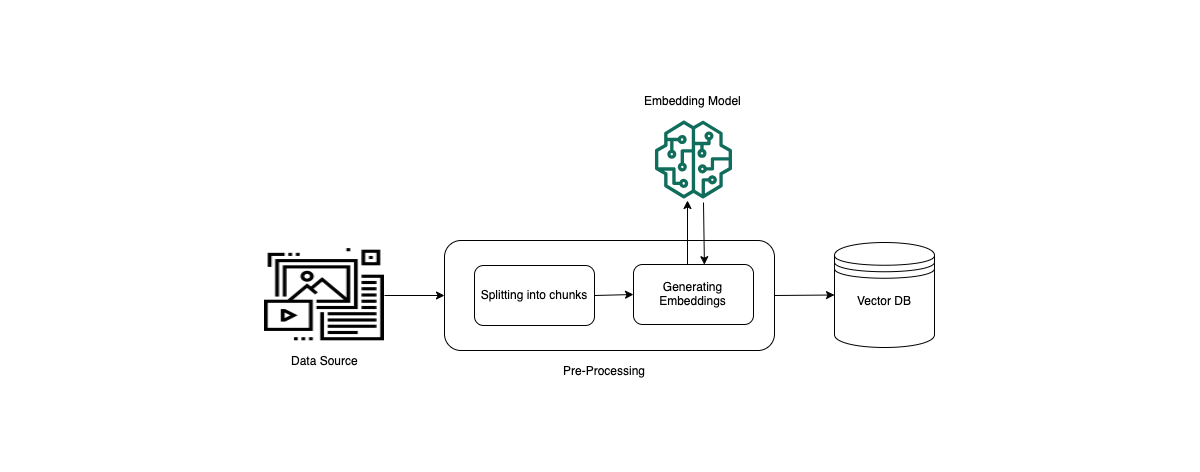
プライベート データから効果的に取得できるようにするには、まずドキュメントを管理しやすいチャンクに分割し、効率的に取得できるようにするのが一般的です。次に、チャンクは埋め込みに変換され、元のドキュメントへのマッピングを維持しながらベクトル インデックスに書き込まれます。これらの埋め込みは、クエリとデータ ソースからのテキストの間の意味的な類似性を判断するために使用されます。次の図は、ベクトル データベースのデータの前処理を示しています。
ランタイム実行
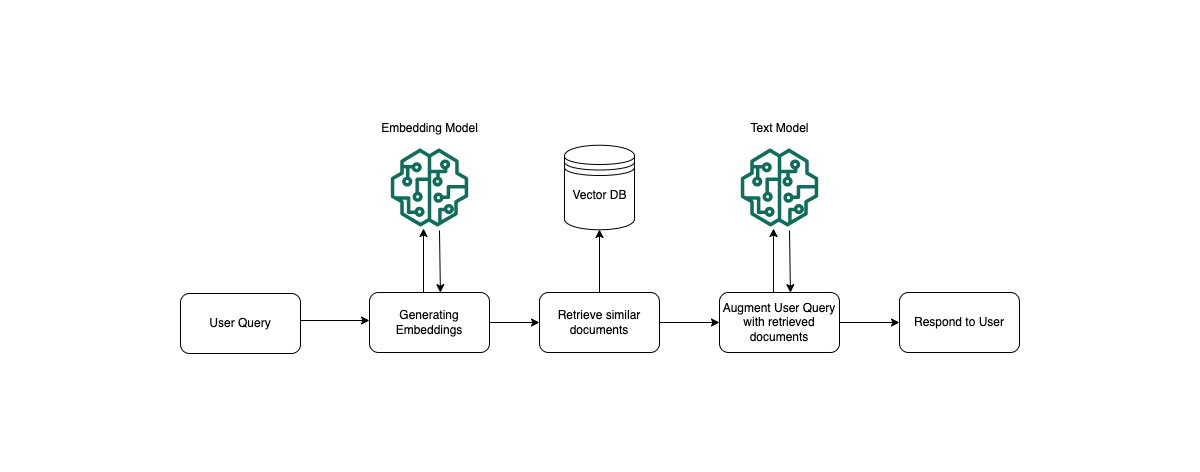
実行時に、埋め込みモデルを使用してユーザーのクエリをベクトルに変換します。次に、ベクトル インデックスがクエリされ、ドキュメント ベクトルとユーザー クエリ ベクトルを比較することによって、ユーザーのクエリと意味的に類似したチャンクが検索されます。最後のステップでは、ユーザー プロンプトが、ベクトル インデックスから取得されたチャンクからの追加のコンテキストで拡張されます。その後、追加のコンテキストとともにプロンプトがモデルに送信され、ユーザーへの応答が生成されます。次の図は、RAG が実行時にどのように動作してユーザー クエリへの応答を強化するかを示しています。
「チャンク」は、テキストを意味のある塊(例:文章を単語やフレーズ)に分割する処理のことで、テキストの意味を理解しやすくするために使用されます。
「ベクトル」は、テキストや単語を数値で表現したもの。テキストをベクトル化することで、コンピュータがテキストを理解しやすくなります。ベクトル化されたテキストは、類似性の計算や機械学習モデルへの入力として利用されます。
Amazon Bedrock では複数のモデルをサポート
Amazon Bedrock には、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon などの大手 AI 企業のモデルが用意されていますが、弊社では Anthropic Claude 2.1 を使用することにしました。
Anthropic Claude 2.1
Claude 2.1 は Anthropic の最新の大規模言語モデル (LLM) で、業界トップクラスの 20 万トークンのコンテキストウィンドウを備え、ハルシネーションの発生率が低下し、長い文書でも精度が向上しています。

Slack で使いたい
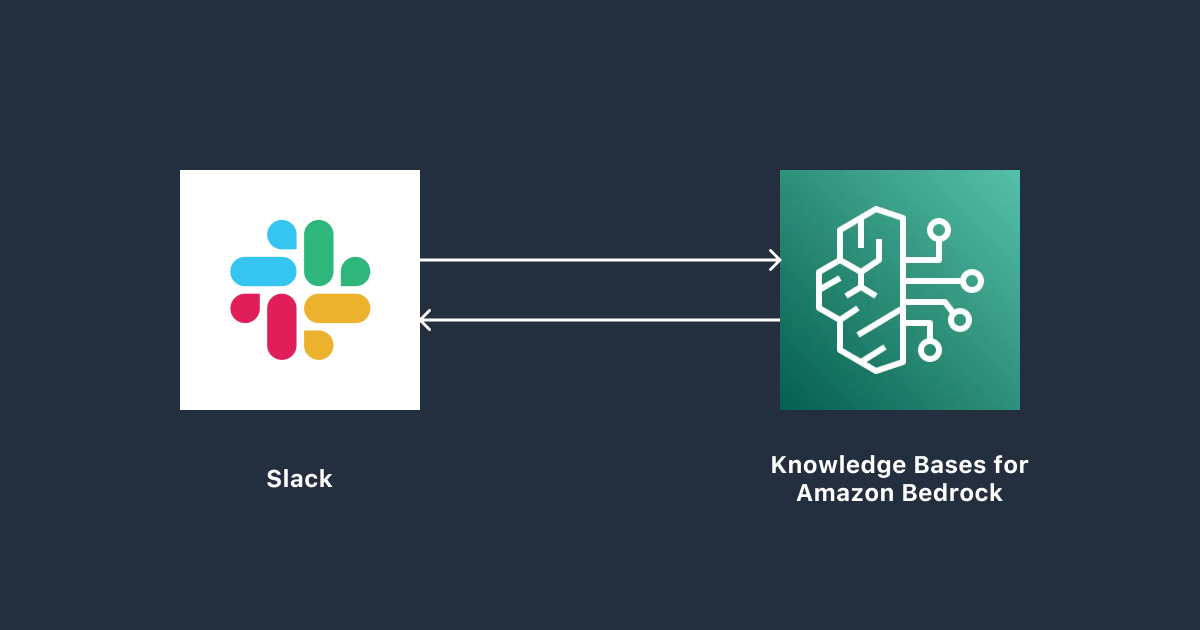
弊社の就業規則や、その他ガイドラインなどを Amzon S3 にアップロードし、社内ナレッジの RAG として運用していこうとしたのですが、
ナレッジベース上で用意されているチャットインターフェイスだとAWSアカウントでログインする必要があり、せっかく便利なものなのに不便に感じてしまいました。
それなら、弊社がコミュニケーションツールとして日々利用している Slack のインターフェイス上から AI に質問できるようにしたらどうか?ということで、seeds-bot という Slack アプリを用意してもらいました。
Slack との連携については次のような感じで使えるようになっています。
詳しい内容につきましては、SEEDS Creators Blog『 Slack から Knowledge Bases for Amazon Bedrock に質問できる「社内ナレッジ AI ChatBot」を作ってみた [RAG] 』 にまとめてくれていますのでそちらをご覧ください。
@seeds-bot
Slack から @seeds-bot に質問することでチャットボットが回答してくれます。

質問後、回答されるまでの間は「考え中」の絵文字が表示されるのもかわいいです。
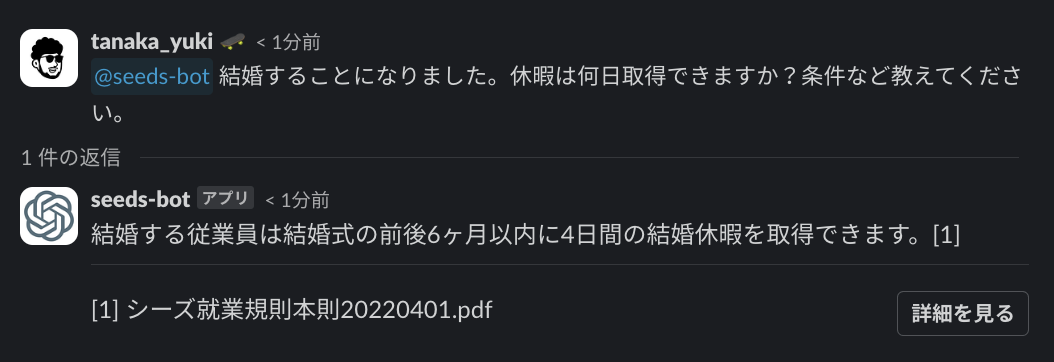
チャットボットからの回答には、元ソースも付いて詳細も見れるようになっています。
Slack から S3 にデータソースを直接アップロードしたい
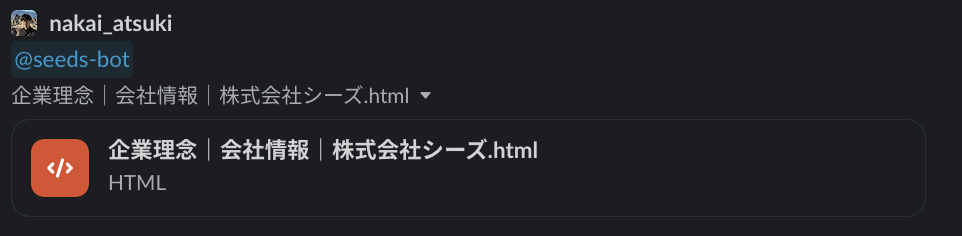
人の欲望は尽きないもの。Slack で使えるようになって便利になってくると、次は Amazon S3 にデータソースをアップするのさえ手間に感じるようになります。
それならば!ということで、今度は Slack から Amazon S3 に直接アップロードでくるようにしてくれました。感謝!
まとめ

ということで、今回は「社内ナレッジ AI ChatBot の活用をはじめました」というご紹介をさせていただきました。
まだまだ始めたばかりなので、これから運用していくなかでいろいろと問題など出てくるかもしれませんが、気になる AWS の利用コストと合わせてまたブログにてご紹介していくつもりです。
現時点では社内での利用を目的とした活用となっていますが、今後、弊社各サービスについての FAQ や、お問い合わせなどの用途にも活用していこうと考えています。
Amazon Bedrock の ナレッジベースを使えば簡単にはじめることができますので、もしご興味がありましたらお気軽にお問い合わせください。