

こんにちは。システム開発事業部の中井です。
先日のAWS re:Invent 2023にて、Amazon Bedrockで検索拡張生成 (RAG) が簡単に実現できる、Knowledge base機能のGAがアナウンスされましたので、実際に触れてみます。
RAGの重要性
まずRAGとは、企業の独自データや最新のトレンドなどの、大規模言語モデル (LLM) が本来持たない外部情報を参照し、それらを基に回答を生成する手法です。この手法は、FAQなどの顧客・従業員サポートや営業支援において特に有用で、より正確な情報が提供可能となります。
これまでは、外部情報のベクトル化やVector storeへの追加をユーザー側で実装する必要がありましたが、今後はこの辺りをKnowledge baseが担ってくれるようになります。
触ってみる
早速、Amazon Bedrockのコンソールから「Knowledge base」を開きます。2023/12/5時点では、us-east-1 (N. Virginia) と us-west-2 (Oregon) でのみ利用可能です。
「Create knowledge base」を押してみます。
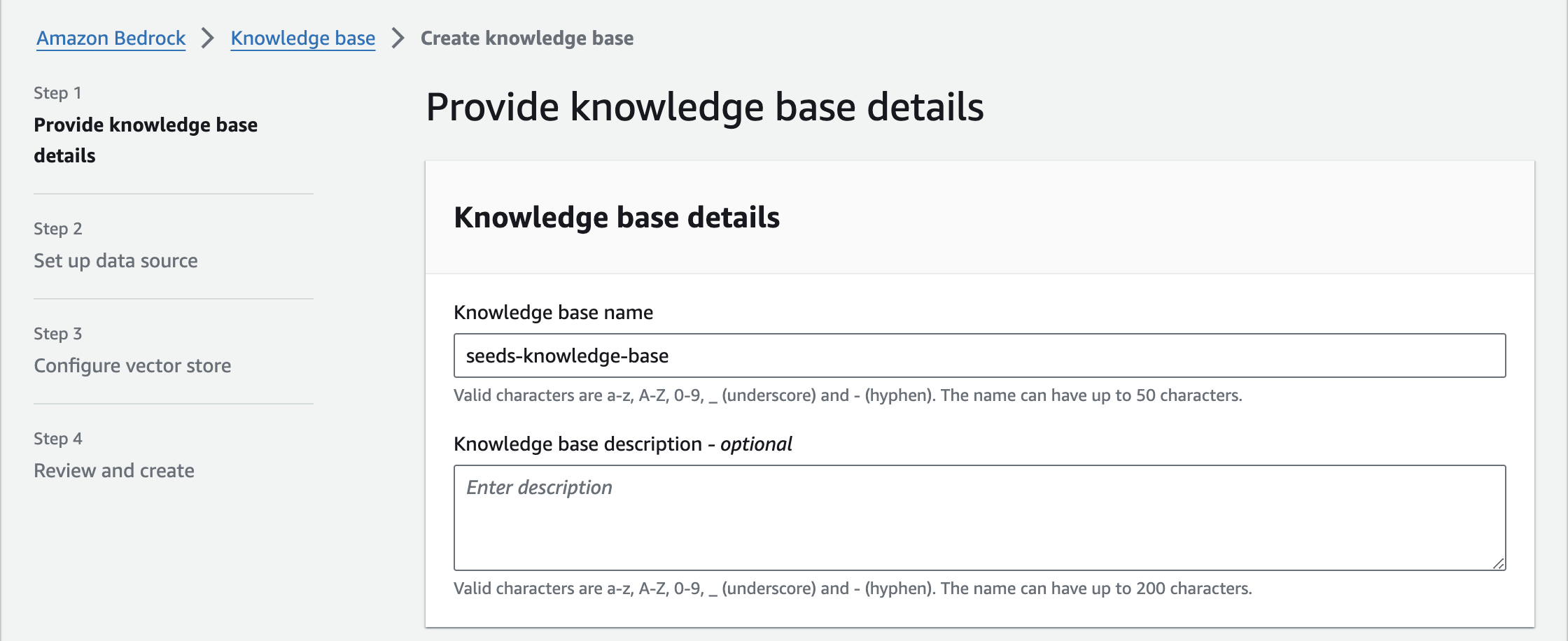
基本情報
今回は名前を「seeds-knowledge-base」、IAM Roleを新規作成にして進めます。
データソース
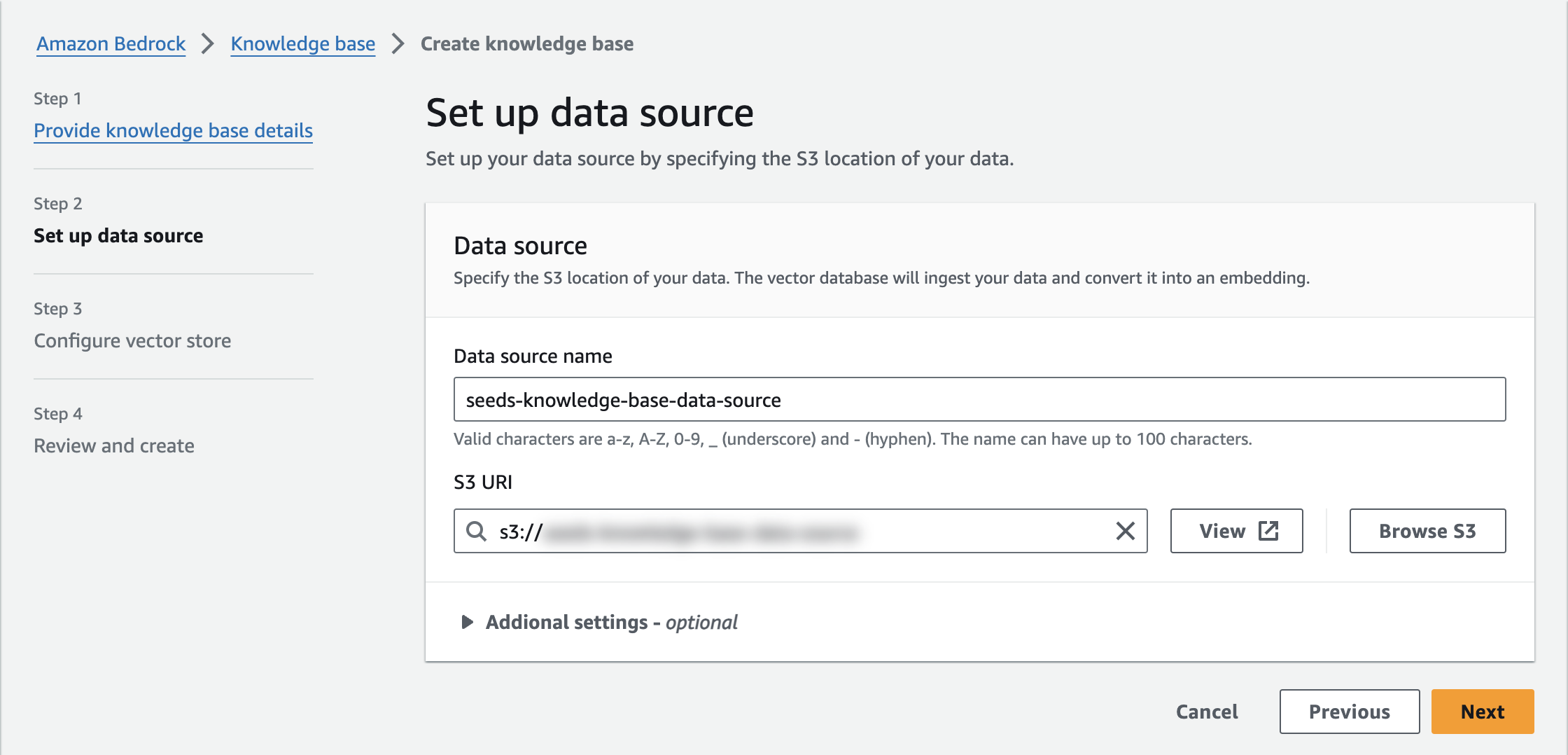
次に、外部情報の置き場所であるデータソースを指定します。準備としてS3バケットをKnowledge baseと同じリージョンに作成し、独自データなどを配置します。今回は弊社コーポレートサイトのHTMLファイルをアップロードしてみました。
・Plain text (.txt)
・Markdown (.md)
・HyperText Markup Language (.html)
・Microsoft Word document (.doc/.docx)
・Comma-separated values (.csv)
・Microsoft Excel spreadsheet (.xls/.xlsx)
・Portable Document Format (.pdf)
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-setup.html
データソースとして、先ほどのS3バケットを指定します。
Vector store
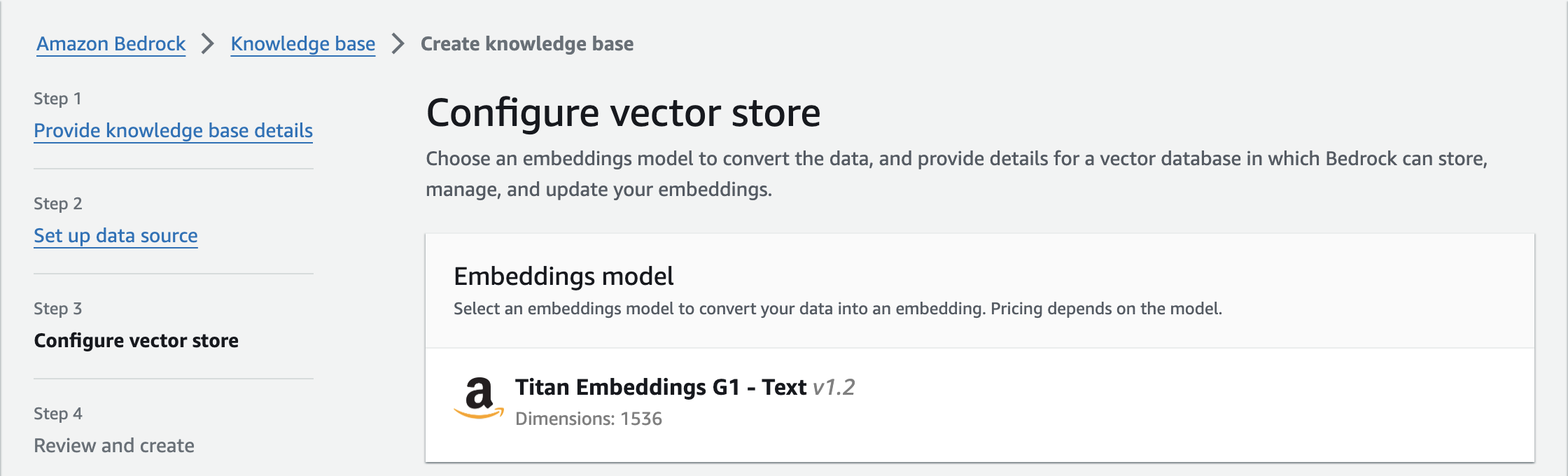
続いて、Vector storeを設定します。現状、埋め込みモデルはTitan Embeddings一択となります。
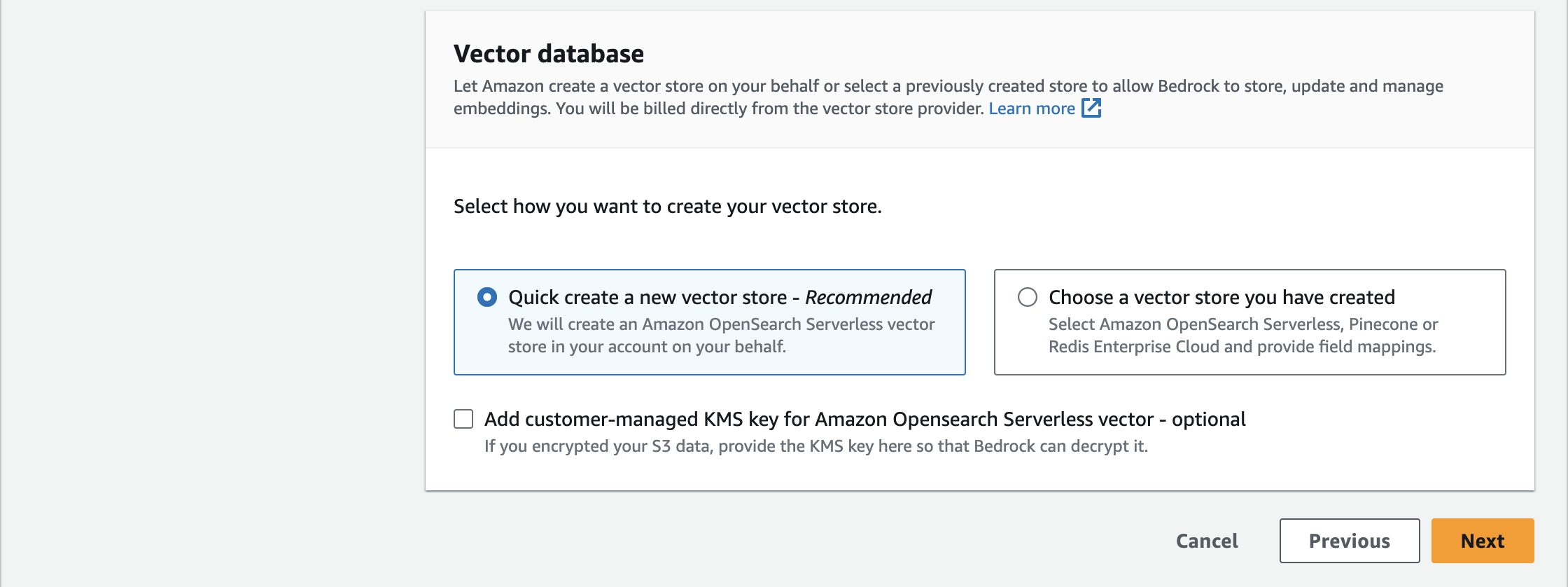
Vector databaseはOpenSearch Serverlessで新規作成するか、既存のものから指定するかを選択できます。後者の場合はOpenSearch Serverless・Pinecone・Redis Enterprise Cloudの3つから選択できるようです。今回は新規作成します。
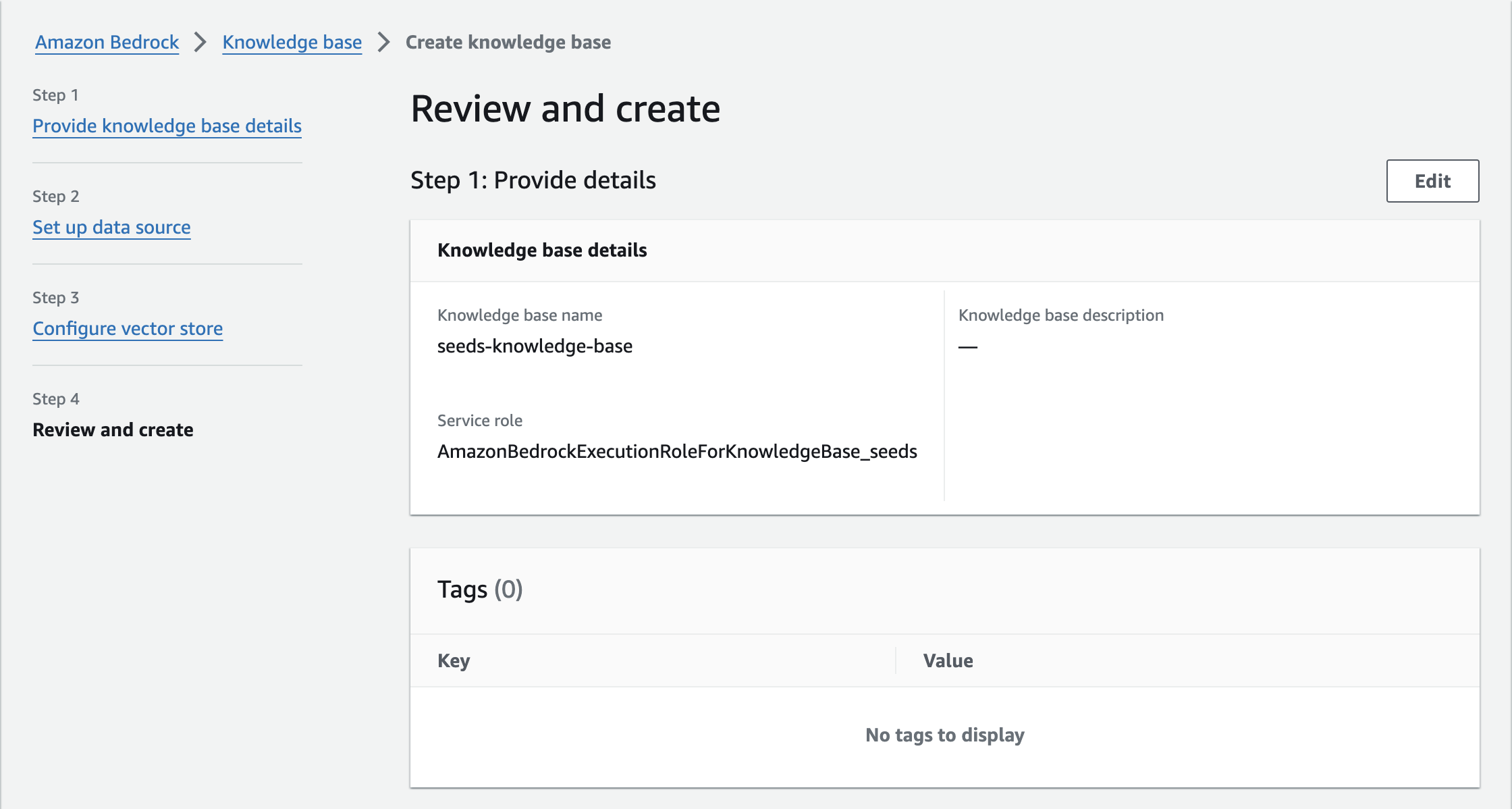
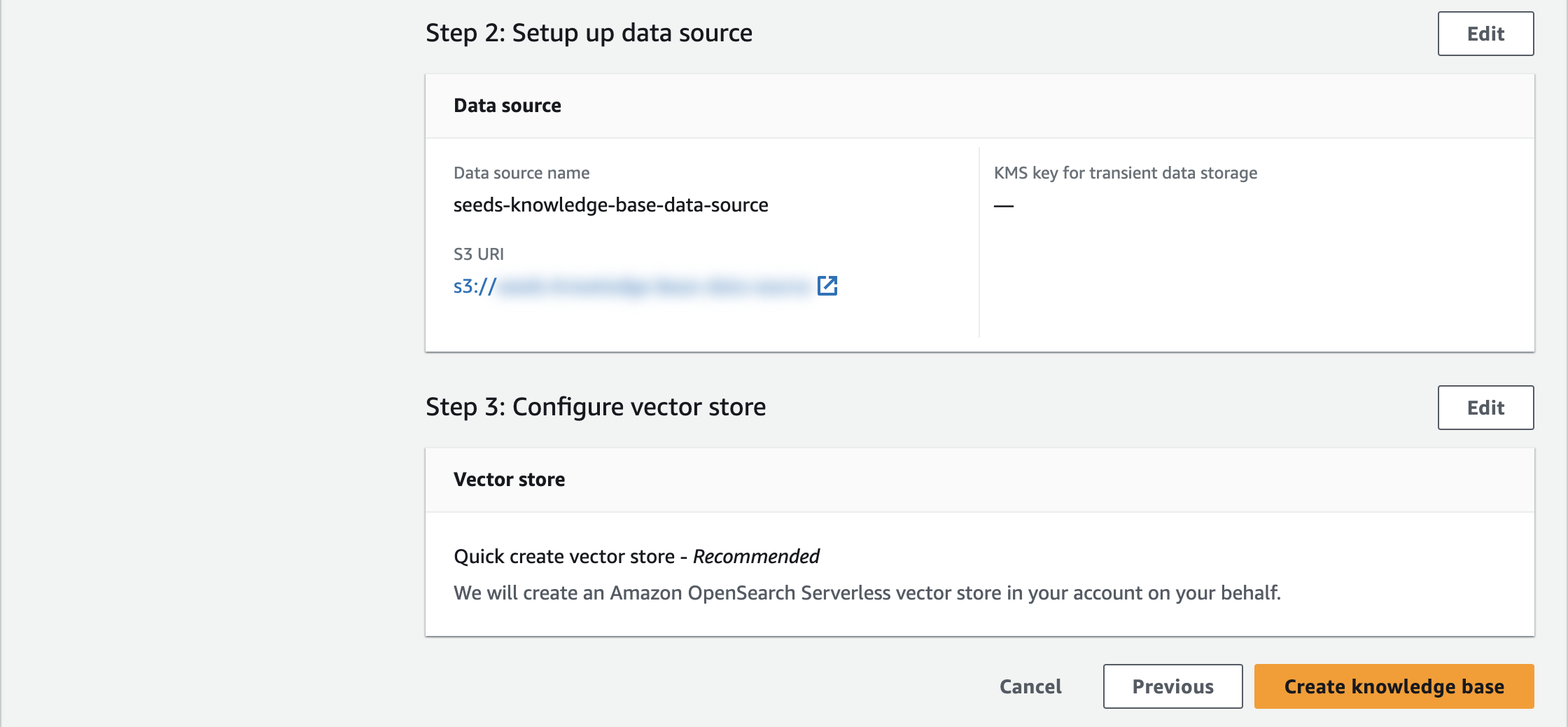
確認画面
内容を確認したら「Create knowledge base」を押します。
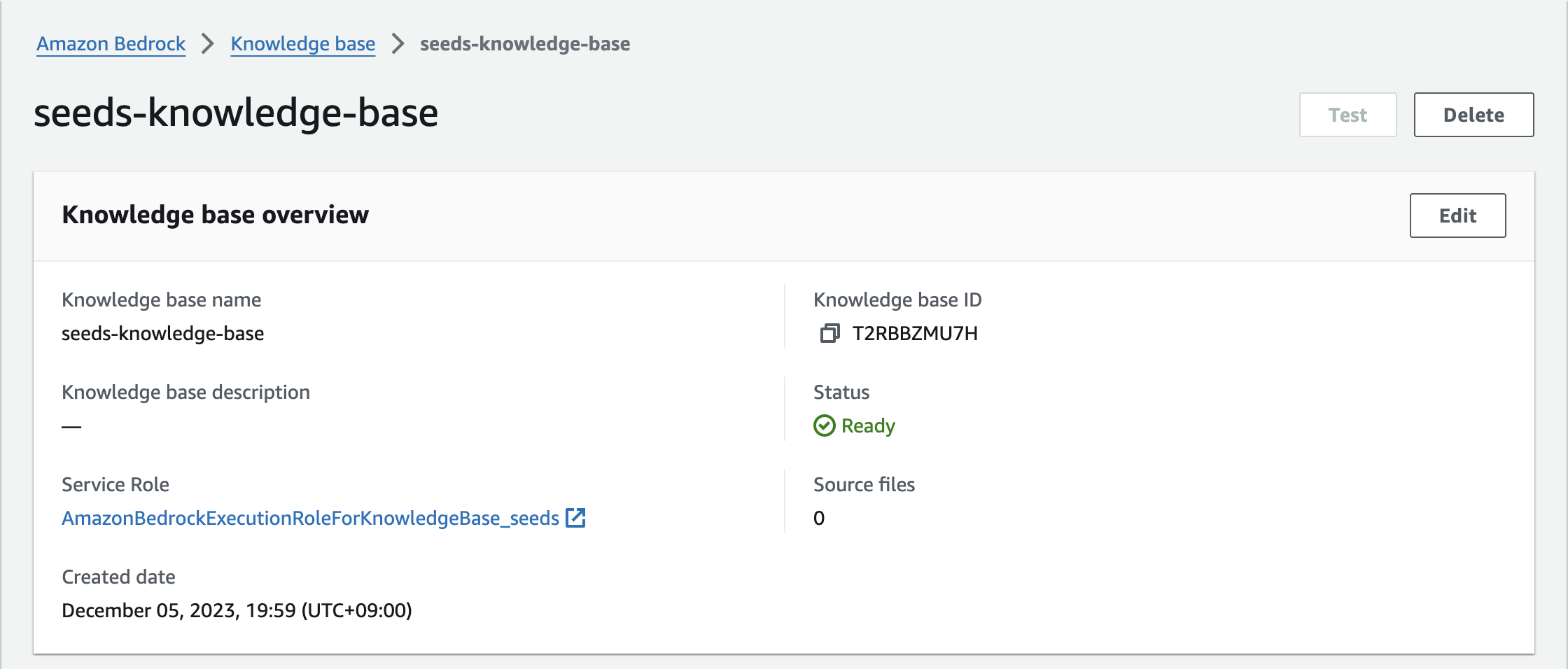
StatusがReadyになるまで待機です。
データソースの同期
初回構築時やデータソースのS3を書き換えた場合、「Sync」で同期を実行する必要があります。

使ってみる
データソースの同期が完了するか、画面上部の「Test」ボタンを押すと、コンソール上にチャットウィンドウが表示されます。テキスト生成のためのモデルを選択する必要がありますので、今回は同じくAWS re:Invent 2023で発表された「Claude 2.1」を使ってみます。
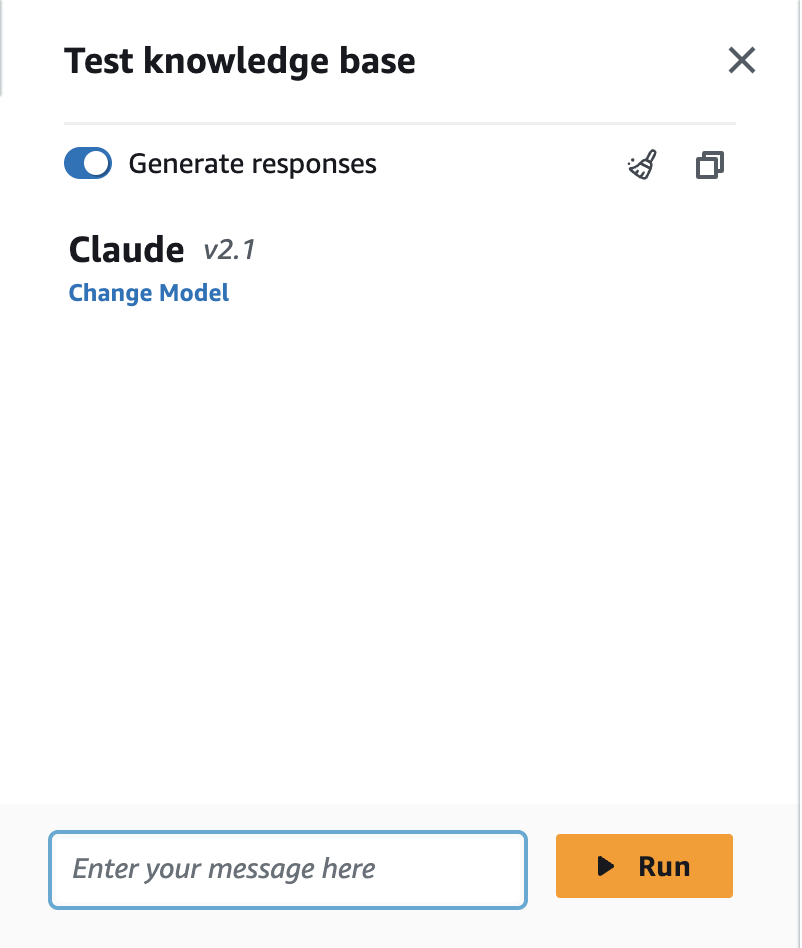
弊社の会社概要について尋ねると……
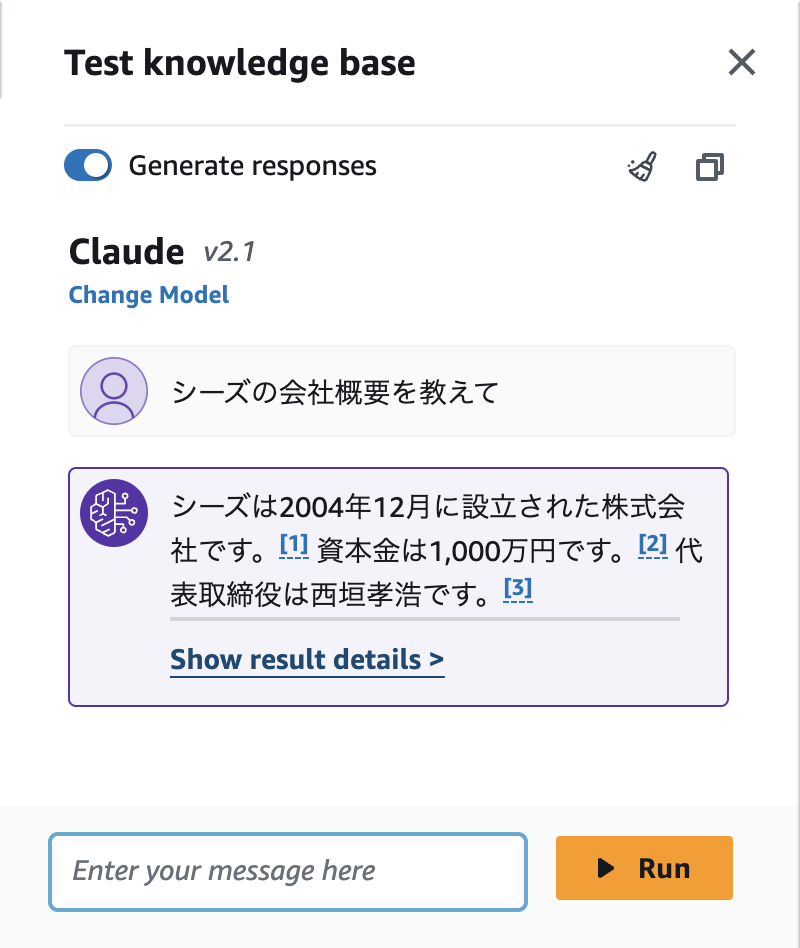
正常にデータソースが参照され、正しい情報が返ってきました!
まとめ
今回はKnowledge baseの作成から、外部情報を基に回答が生成されるところまで確認しました。
これらの機能はAPI経由でも利用可能ですし、LangChainなどと連携させることも可能です。
Knowledge baseを活用することで、RAGの実装にリソースを割くことなく、ユーザーデータの管理やシステム構築の方に集中できるようになりそうです。今後の発展にも期待が高まりますね。
