
クラウドソリューション事業部の原口です。
今年ももう終わり。これが僕の2022年最後のブログ更新となると思いますので、今年で一番頑張ったなーと思っているプロジェクトをご紹介したいと思います。
セール時は大量の商品注文が入るEC-CUBEサイトをリプレースしたお話です。
もともとの構成
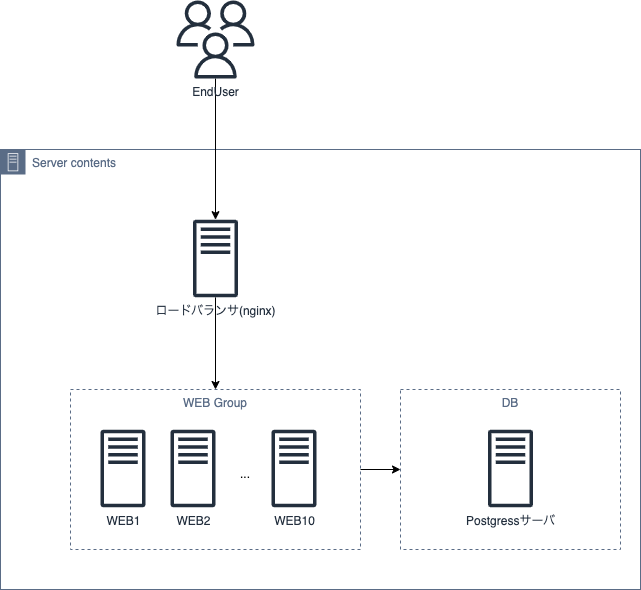
もともとは国産クラウドにて上記のような構成となっていました。
WEBにEC-CUBEが入っててDBは別になっている形です。
WEBの同期はWEB1をサーバーとしたlsyncで行われていました。
サイトの特性として、セール時は超高負荷となりますが、セールしていない時期の負荷はほとんどありませんでした。そのため、セール実施の1時間前くらいに以下のような作業でWEBをスケールするという運用がされていました。
・WEB1のスナップショットを手動で取得
・スナップショットからWEBサーバーを任意の数だけ手動で作成(大体WEB10まで)
・nginxにて新規作成したサーバーへの振り分け設定を手動で追加
・手動でPostgressサーバーのスペックをアップ
セール終了後は逆の操作を手動で行います。
面倒ではありましたが、上記の運用で騙し騙し動いてはいたそうなのですが、セールのたびに訪問者数は増え、ついにWEBをいくらスケールしても耐えきれなくなってきており、そんな時、シーズへ相談がありました。なんともやりがいのある構成ですね!
対策案
調査の結果、EC-CUBE自身やプラグインの仕様の問題でDB負荷やデッドロックしてしまうところが原因である事はわかりましたので、EC-CUBEを弊社のフルスクラッチのECシステムに載せ替える事は決定していましたが、目の前のまともにセールができない状況の改善の優先度が高いので、以下のような形で恒久対応を行う事となりました。
Phase1
現状のプログラムのままAWSへ移行し、可能な限りマネージドサービスを利用する
Phase2
ECサイトをフルスクラッチ開発する。
Phase3
クラウドネイティブな環境へデプロイし既存環境をリプレースする
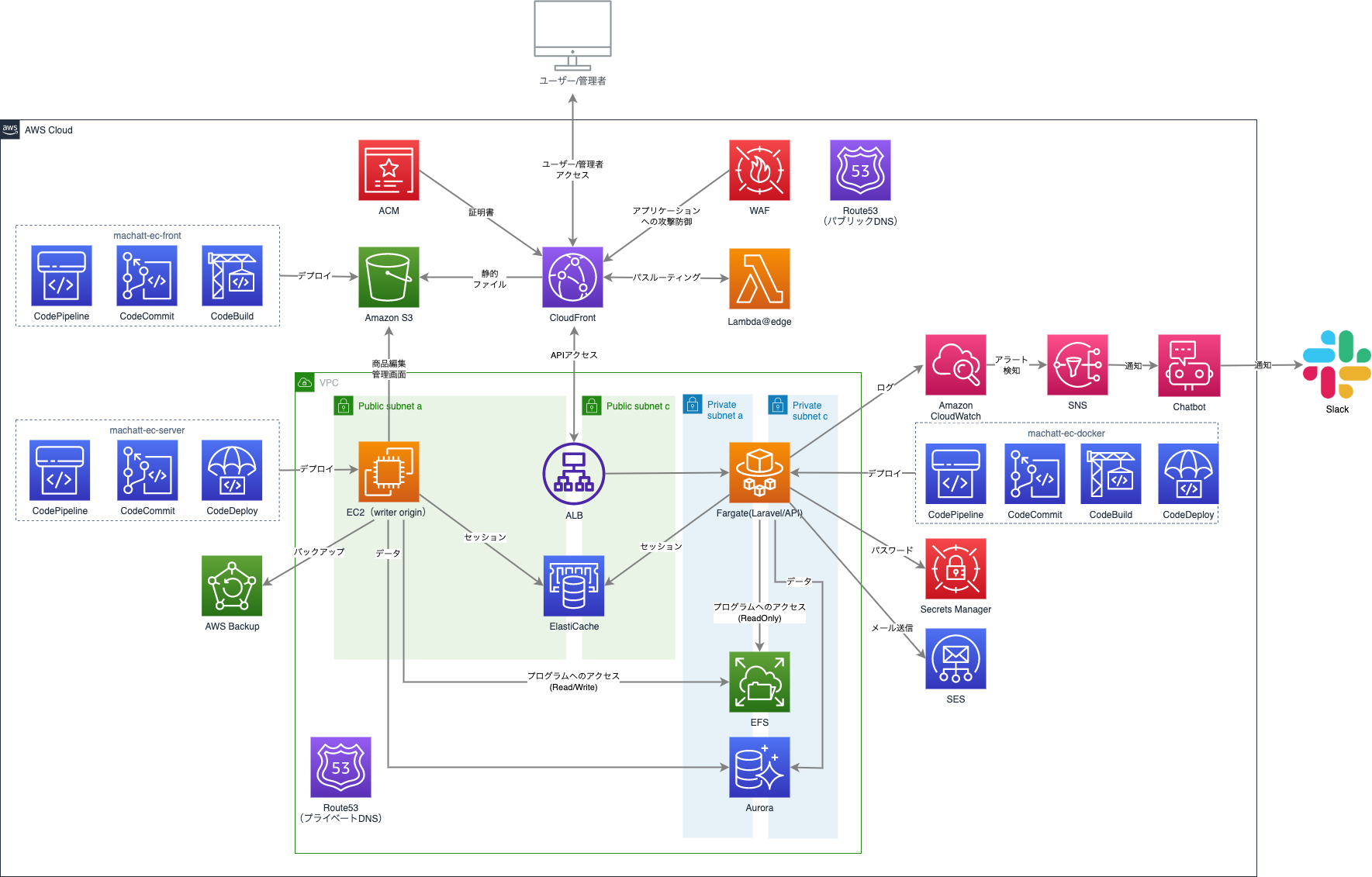
Phase1 AWSへの移行
Phase1では以下のような構成としました。
AWSに移行するだけとはいえ、そのままではこれまで同様に落ちてしまうので以下のようになっています。
・cloudfrontにて静的ファイルをキャッシュする
・Auroraでクラスター構成を組み、検索のみのクエリをreaderのみに振り分けるなどの改修する事でDB負荷を分散させる
・セッションをElastiCacheに保存するように修正
・EC-CUBEにおけるステートフルな項目(ディレクトリ)のみEFSに保存するようにしてlsyncの利用をやめる
・Adminサーバを作りこのインフラ(OS/ミドル)修正時はサーバーのAMIを取りローリングデプロイするように設計
・セール時のEC2やRDSのスケールをCodebuildの実施一つで行えるようにする事で運用コストを削減
王道的な構成ですが、こちらの構成で取り急ぎの「セール時に動かなくなる」という問題は解決しました。ただし、この構成でも増え続ける利用者の増加を考えるといつか限界は迎えますし、コストも増大していくでしょう。ここでできた時間を使いシステム開発を行っていきます。
Phase2 ECサイト開発
弊社は印パケという印刷通販用のECサイトパッケージを開発していますのでECサイトに関する知識があったので全体的に必要なタスクとかかる時間などは容易に出す事ができました。プロジェクトのフルメンバーは僕(PM,プログラム,インフラ)とプログラマ1名。フロントエンド1名。の合計3名。ここにヘルプのメンバーが3,4名という形で開発しました。結論だけ書くとこのメンバでおよそ2ヶ月で開発完了しています。
これは画面設計などの部分について先方がこちらをプロとして信頼していただけていた事もあり先方への確認においての手戻りがほとんどなく進んだ事が大きいです。
見返すとメインの人たちのコード量やばい
タスク管理
タスク管理は弊社では基本的にバックログを使う事が多いのですが、この案件ではGitHubのIssueのみで管理しています。プルリクとIssueの繋ぎが簡単ですしラベルでの管理などもできるので今回の開発では必要十分でした。
GitHubのIssue
・PMやデバッガーが中心にIssueを登録し優先度などのラベルを付ける
・開発者が問題解決したりといった対応し、対応できたらfixedタグをつける
・Issue登録者はfixedのタグがついているものを動作確認して、問題なければIssueをclose
こんなゆるいルールで運用しています。
アーキテクト
全体構成としてはバックエンドはAPIサーバーとして、フロントからCSRする形を選択しています。バックエンドはlaravelを選択しました。これはシーズが得意なフレームワークである事が理由として大きいです。高負荷時のスケール速度と脆弱性管理の保守コストからEC2の選択はなし、ですので必然的にコンテナで運用する形となりました。フロントはnext.jsを選択していますが、運用コストからnext.jsのサーバーを立ち上げる事はせず、exportした静的ファイルをs3にあげる形としています。本来はSSRやISRすべき所ですのでこのあたりはちょっと歪ですね。
設計
データベース設計は基本的にEC-CUBEを倣いました。当初の要望としてユーザ情報や商品データを引き続き利用する必要があるというところから始まったのもあり、EC-CUBEでのDB設計を倣い、プログラム側における不要な機能を削ってシンプルに実装しなおした方が良いだろうという風に思ったからです。この時はEC-CUBEのコードを見まくりました。すでにECサイトとしての実績は当然なのでこちらに倣うと考慮漏れが無くなるだろう、という事も考えました。
結果的にこの判断は正しく、設計の手戻りも出来上がったシステムの機能においても先方との認識の差もほとんどありませんでした。注文フローはかなり簡素化しましたのでそのあたりだけきちんと設計し説明しましたが、画面設計などの工数をがっつり削減できた事は大きいです。
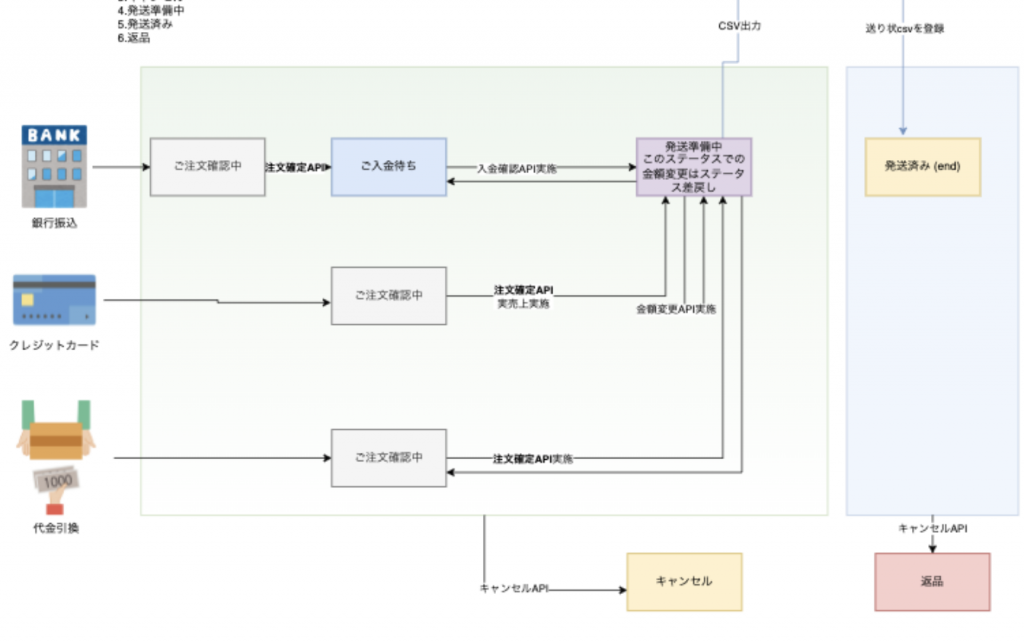
開発中の注文フロー仕様
APIテスト(php-unit)
バックエンドがAPIのみなのでテストは非常にやりやすいです。laravelのテスト機能(php-unit)を使いました。初回の頃はテストを1度行うと1つのAPIテストごとにDBマイグレーションしていて10分くらいかかっていたのですが、西村さんが並列実行や不要な箇所でのマイグレーションをしないようにする事で1分くらいで終わるようにしてくれました。

現在も75秒。早い!
全部の関数をテストするようなものではなく、機能ごと、例えば「注文処理」(商品を買って購入したら在庫が減って注文履歴が増える)みたいな単位のテストをメインとしていました。単体テストも行っていますが、、、クリティカルな項目だけでもテストは用意しておくと心理的安全性も高まりますし何よりも本番における不具合を大きく減らす事ができますので忙しくても実装するのがおすすめです。
最終的にはこちらのテストはGitHub Actionsで実行するようにし、プルリクエストはテストが通っていなければmainへのマージができない形としています。
脆弱性診断
弊社では作成したシステムはOWASP ZAPの脆弱性スキャンを実施する事が義務付けされています。今回はAPIですのでZAPのスパイダーによるURLスキャンなどではなく、OpenAPIで用意したAPI仕様書に対してスキャンを実施するようにします。必然的にAPIドキュメントも出来上がりますし、外部の脆弱性スキャンを行ってくれるベンダーに対してもOpenAPIのAPI仕様書を渡すだけなので楽ですね。
Phase3 AWS ECSへデプロイ
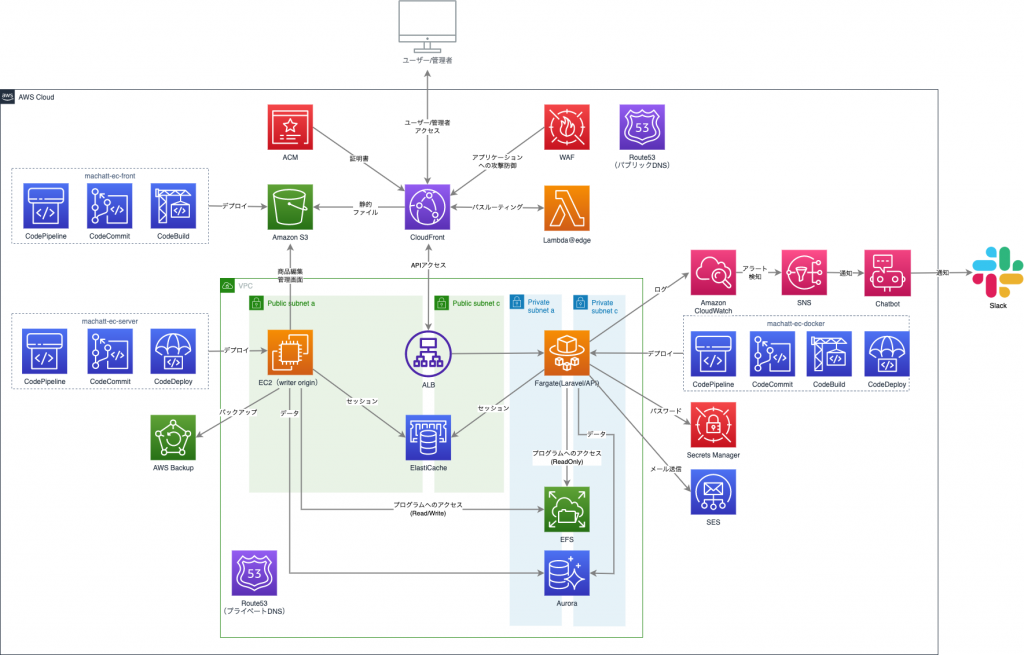
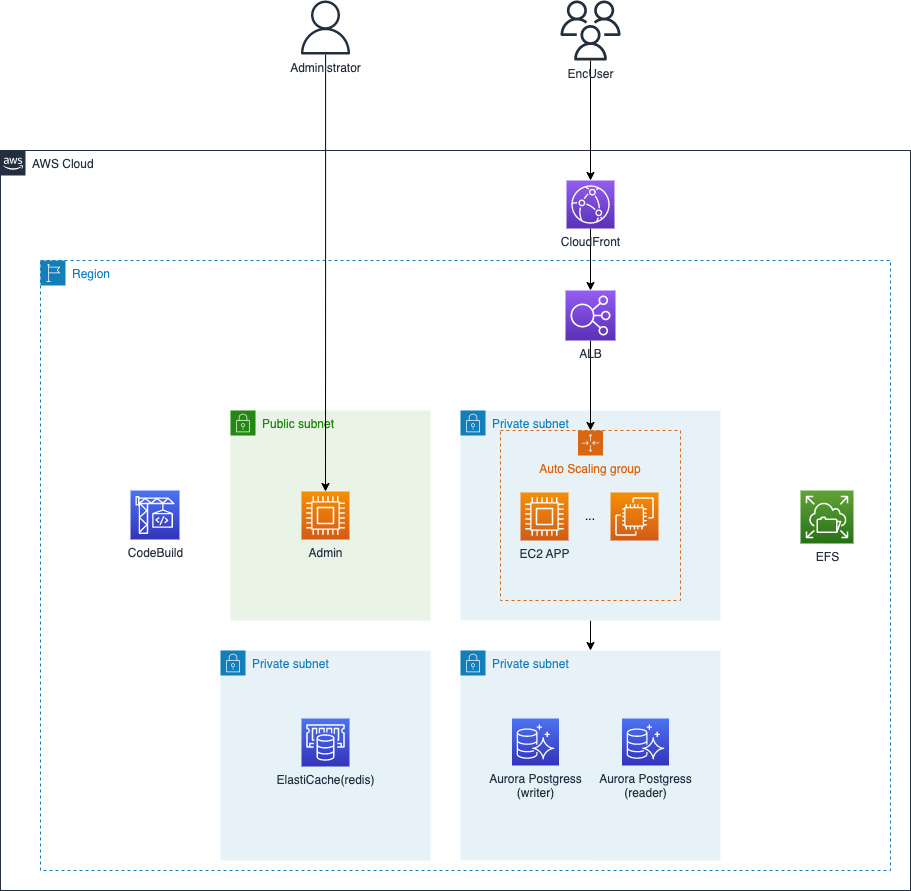
いきなりですが最終的な構成図です。
Phase3とは書きましたがわりと早い時点でミニマムな本番環境は用意し、CI/CDフローは開発中から動かすようにしていました。CI/CDはブランチや設定ファイル、環境変数の持ち方に密接に関わってきますのでプログラムの仕様に関わる恐れがある事と、CloudFrontやALBを挟む事による予期せぬ問題はできる限り早く出しておくべきと考えるからです。同様の理由で本来であればstaging環境などもこのタイミングで考えておくべきかと思います。
コンテナ環境のstaging作成はわりとハマる事が多いので(後ほど苦労する事となりました;)
環境変数の持ち方
laravelの環境変数は.envで持ちます。本番環境がコンテナであるので思想としては「Docker imageは全環境で同じで、環境変数を与えるだけで振る舞いがstageやtestと変わる!」としたかったのですが、laravelの持つ環境変数が膨大すぎて結局は .env.production や .env.staging などを持つようにしました。
ただし本番環境のみ重要なクレデンシャル情報はSecret Managerで管理するようにしています。
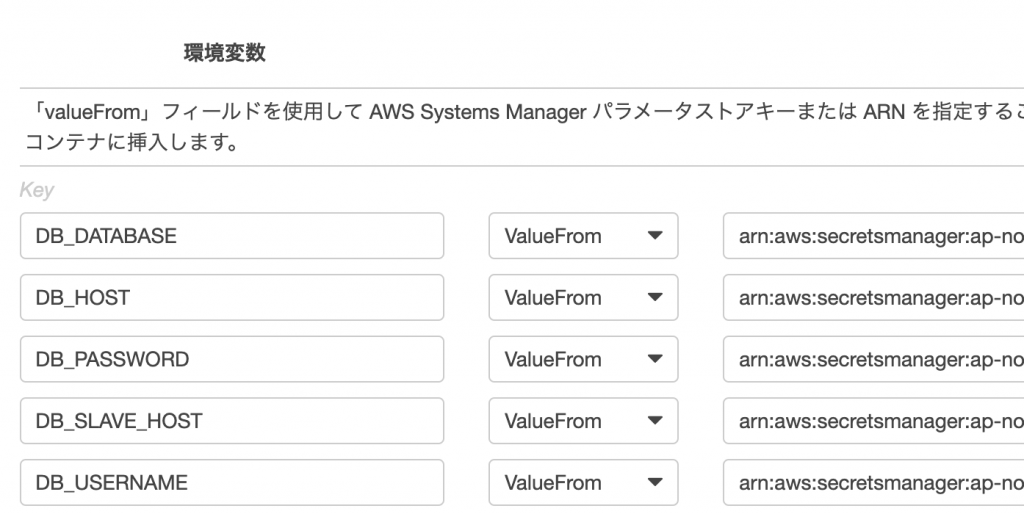
ECSタスク定義のValueFromはSecret ManagerのARNで読み込めます
このようにECSのタスク定義はこの環境変数にSecret ManagerのARNを直で差し込めるので便利ですね。Secret Managerへのアクセス権をIAMポリシーで制限すれば開発者であっても本番DBのパスワードを確認する事はできずに開発できるというセキュリティ的なメリットも生まれます。
Dockerの構成
Dockerfileについては本番用と開発用と、、、と、複数のDockerfileを持ちたくないですが、とはいえ本番と開発ではちょっと違う設定で使いたいというところもあります。(特にphp.iniなど)そこで今回の構成はlaravelコンテナはマルチステージビルドでその差異を吸収しています。
1FROM php:8.1.12-apache-buster AS base
2
3# ベースとなる処理を記述
4
5FROM base AS development
6# 開発環境のみに適用する処理を記述
7
8
9FROM base AS production
10# 本番環境のみに適用する処理を記述
11
12FROM production上記のように記載することでdocker-compose.ymlではビルドのステージを選択できるようになります。
1version: '3.7'
2services:
3 web:
4 build:
5 context: ./docker/web
6 target: developmentそれぞれの記述は例ですが、ポイントは `target: development` のところですね。このように記述することでローカル開発のdocker compose up -d した時はwebコンテナはdevelopまでのレイアー処理されたimageを使う形とすることができます。
CI/CD
CI/CDのパイプラインは「フロント」「docker」「プログラム」の3つを用意しています。AWSのCodePipelineを利用していますが全てのトリガーはCodeCommitとしています。CodeCommitへのpushはGithub Actionsにてミラーリングする形としています。本プロジェクトのリポジトリは1つになりますがそれぞれの修正されたファイルに応じたCodeCommitへのpushが行われる形です。これによりマイクロサービスっぽくそれぞれの更新したい時にその範囲だけのデプロイが行われる形となっています。
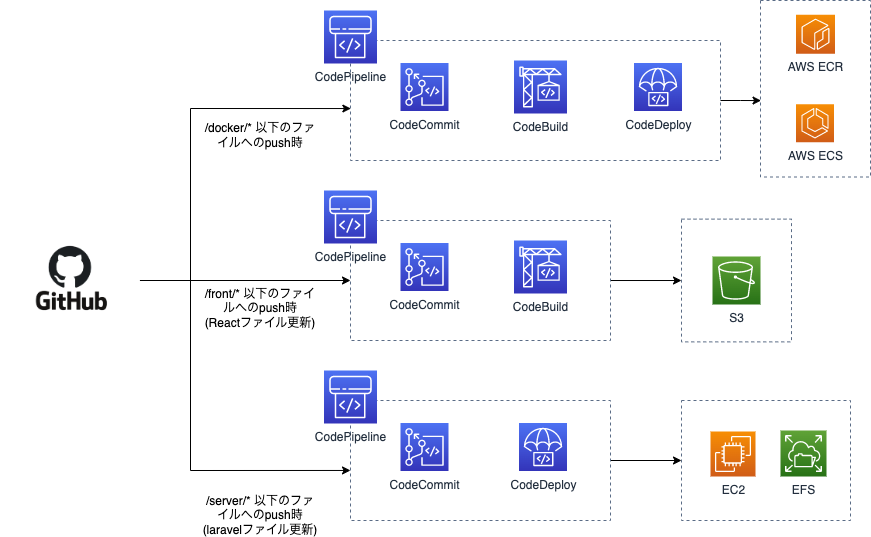
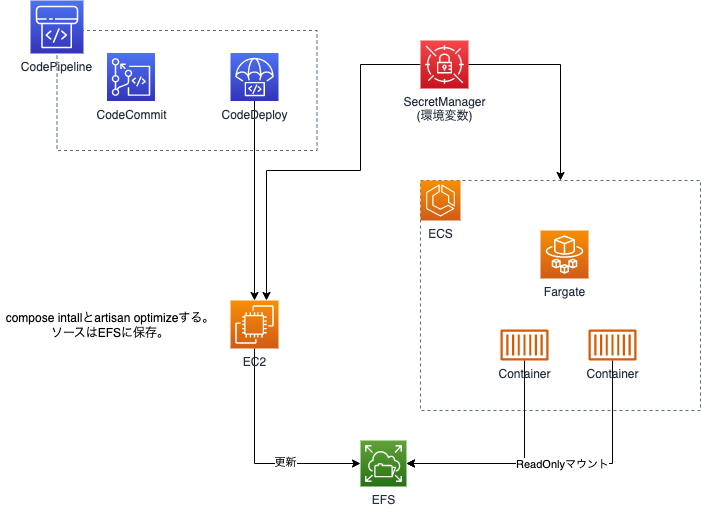
また今回の構成ではPHPプログラムはDocker Imageには含めずに全てEFSに保存しています。これはlaravelの軽微な文言修正であってもDockerのビルドやcompose installが毎度走るのが嫌だというところがあり、これを分ける事でDocker imageのbuildが走る回数をかなり減らせるのではないかと考えたからです。ですのでデプロイはEFSをマウントしたEC2で基本的にgit pullだけとなっています。ECSのタスク定義では簡単にEFSをマウントできて便利ですね。ここだけEC2が存在してしまっていますがシステム自体はコンテナで動かしている事と、cronなどの実行については利便性が良いのでこの形としています。
フロントエンド
今回、next.jsではありますが、yarn exportでできた成果物をs3にあげるという方法をとっています。CodeBuildにて「NODE_OPTIONS: –max-old-space-size=4096」といったオプションをつけるなどのカスタマイズは行いましたがCodeBuildのみでデプロイができ、概ね問題なくできていました。が!
所謂EC2などで運用した場合、Apacheやnginxなどを利用することが多いですが、rewriteというURLの書き換えを行う機能が存在します。SPAなどのサイトを構築する場合は、このrewriteという機能を利用してURLを書き換えることで、/product/1 などのURLでも /product/index.html を表示するといった事を実現し、データをAPIから取ってきてレンダリングするという事が可能なのですが、、、S3にはこのrewrite機能がありません!
この部分は上位のCloudFrontからLambda@Edgeを使い、lambdaでURL書き換えを行なっています。
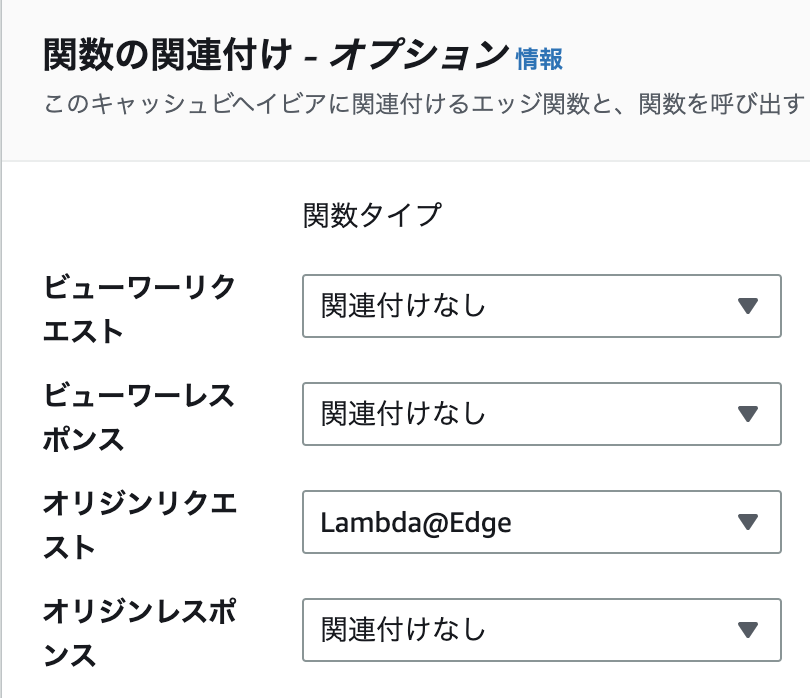
CloudFrontからシームレスにLambdaを呼べます
このあたりをサクッと実装してくれた石田さんは本当にレベルが高いと思います。
セキュリティ
フロント
s3で公開していますので、OS/ミドルの脆弱性は考える必要がないと言えます。また静的ファイルのみなので脆弱性については優先度を下げれる環境となっています。
API(laravel)
ヘッダやCSRFトークンなどを都度発行するなど、基本的なことではありますが、laravelの機能とベストプラクティスを使う様に心がけています。このあたりはlaravelにめちゃくちゃ強いプログラマがいますのでかなりお世話になりました。
AWS WAF + CloudFrontがメインでAWSのマネージドルールを適用しています。ELBに対してはCloudFrontからの接続のみを接続するようにセキュリティグループでプレフィックスリストを利用しています。便利ですよね、プレフィックスリスト。
コンテナ
コンテナをreadOnlyコンテナで動かすという形にこだわりました。また、codebuildにてimageの脆弱性チェックも行なっています。
これらについては過去のブログで詳細を書いてますのでぜひご参照ください!
コンテナのセキュリティ対策!AWS ECS (fargate)でタスクをreadonlyRootFilesystemで運用する
https://www.seeds-std.co.jp/blog/creators/2022-02-08-114520/
WordPressをコンテナでセキュアに構築/運用
https://www.seeds-std.co.jp/blog/creators/2022-03-31-235602/
AWS Codebuildのコンテナイメージ”ARM64″を利用する際にAWS CLIの注意点
https://www.seeds-std.co.jp/blog/creators/2022-05-17-123302/
AWS ECSのCodePipeline(blue/green CodeDeploy)におけるtaskdef.jsonをcodebuild内で作成する。
https://www.seeds-std.co.jp/blog/creators/2022-05-19-212840/
高速化
大きな問題としてプログラムソースはEFSに入れ、コンテナでマウントしている事からここの速度の遅さが懸念としてありました。
これはAWSの Best Practices for WordPress on AWS などにも記載されている解決策が利用できます。
要約してしまうと「OPCacheを使え」という話でして、PHPファイルのプリコンパイルされたスクリプトバイトコードを共有メモリに格納することで、そもそもの元ファイルであるEFSへアクセスさせないという施策です。
詳しくは以下の記事の「EFSが遅い問題への対応」をご確認ください。
WordPressをコンテナでセキュアに構築/運用
https://www.seeds-std.co.jp/blog/creators/2022-03-31-235602/
負荷テスト
負荷テストはk6を利用しました。
あらかじめテストシナリオを検討しました。すでにEC-CUBE時代にてアクセスログがありますのでこちらを解析し、「アクセス数の約1/10が商品を購入する」ということがわかりました。例えば1分に16,000アクセスあれば1,600の商品購入がある形です。そのため、テストケースは大きくわけると以下のパターンとしました。
・非ログインで「トップ」と「一覧」と「商品」というページ遷移のシナリオ
・ログインし、カートから決済まで購入を行うシナリオ
この2つのシナリオを10:1で設定し同時接続数を上げていく形です。
k6のプログラム的な実装はプログラマにお願いをして、実施はインフラエンジニアで行いました。

ここで2点、問題が発生します。
一点目は注文処理のシナリオの同時接続数を少し上げる(10並列くらい)だけで500エラーが大量に発生してしまう事態となったことです。調査をしたところどうやら在庫の増減あたりのトランザクションにおけるロックでデッドロックを起こす形となってしまうようでした。該当箇所のプログラムはイメージで表すと以下のような形です。
1try {
2 DB::beginTransaction();
3 注文情報をデータベースに保存;
4 在庫が存在するか最終確認し、占有ロックをかけて在庫を減らす;
5 注文メールを送信;
6} catch (\Exception $e) {
7 DB::rollBack();
8 # -> エラー
9}この中でも特に「注文メールを送信(AWS SESのAPIを叩く)」の処理と「在庫の存在チェック」がネックとなってトランザクションが長くなりデッドロックが発生するということがわかりました。その為以下のような実装に変更しました。
1try {
2 DB::beginTransaction();
3 在庫が存在するか最終確認し、占有ロックをかけて在庫を減らす;
4} catch (\Exception $e) {
5 DB::rollBack();
6 # -> エラー
7}
8
9try {
10 DB::beginTransaction();
11 注文情報をデータベースに保存;
12 注文メールを送信;
13} catch (\Exception $e) {
14 DB::rollBack();
15 在庫を増やす;
16 # -> エラー
17}トランザクションを分けて、在庫テーブルからまずは在庫を減らしてしまって、2つめのトランザクションではエラー時に在庫データを戻す(増やす)という形です。この実装で分間50件くらいの処理で落ちてしまっていたのが分間1,600-2,000ほどの処理ができるようになりました。
2点目は何故か超高負荷をかけると、Segmentation fault (11) となるコンテナが偶発的に発生するという問題です。一度発生すると、高負荷じゃなくても該当のAPIメソッドのみ必ずSegmentation faultになってしまう状態となる問題となります。いっそ死んでくれるならAutoScaleで正常性を保つ事ができるのですが、該当コンテナのその他のAPIは正常に動いていたためヘルスチェックは通過しますし、かなりタチの悪い問題でした。
コアダンプ出力をするにもリードオンリーコンテナの為、非常にやりづらく、さらに超高負荷をかけたからといって必ず発生するものでもなく。。結局原因を見つけることはできませんでした。
ただし負荷テストで出たという事は本番でも出る可能性があるので予防策を実施しておく必要があります。
コンテナはCloudWatch Logsにログを送信していた為、以下のような実装でSegmentation faultがログに出現した場合はそのコンテナを殺すという処理を実装しました。
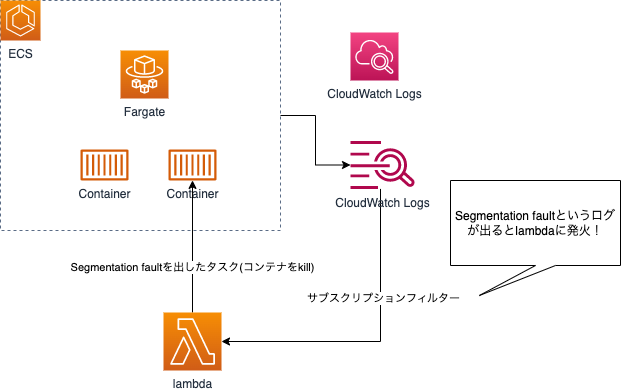
この問題は負荷テストでも発生した日以外は再現できませんでしたし、今の所、この機能が発火した事はありませんので本当に一時的なものだったのかもしれませんが、事前に予防できているのは安心ですね。
この部分も石田さんと西村さんでさくっとlambda実装してくれました。
その他、SESの1日の送信件数の上限に達してしまったり、laravel api側のレートリミットにかかってしまったりといった諸々の問題が浮上しました。
負荷テスト、重要ですね。
ログ
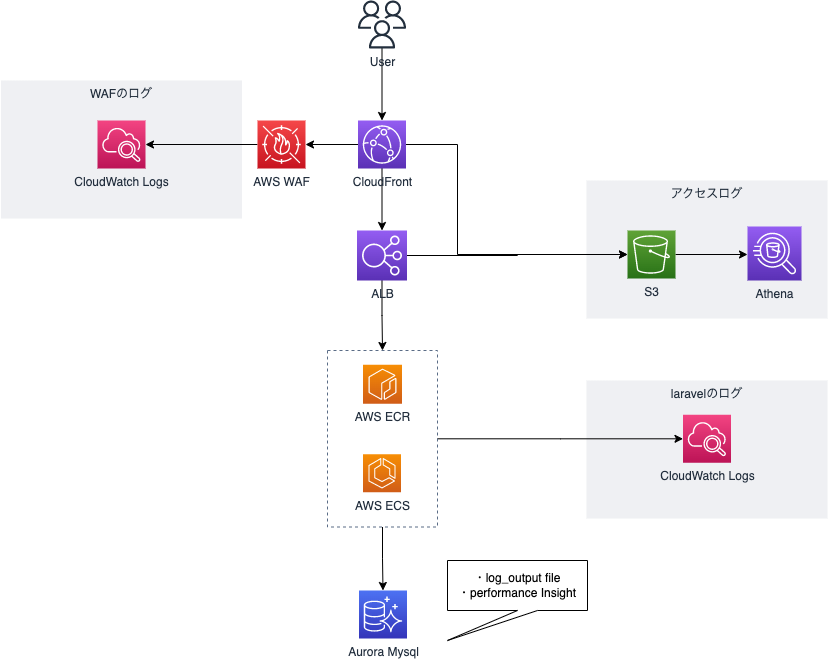
ログ周りは今も試行錯誤しています。やっぱりEC2でログをtail -fとかしていた利便性にはどうやっても追いつけ無いんですよね…
AWS WAF
wafのログはcloudwatch logsを利用しています。アクセスのログは要らないのでBlockとCountのみをログ保存するようフィルター設定しています
CloudFront / ELB
それぞれs3へ保存しています。集計や解析が必要なときにAthenaを使い解析しています
コンテナ
コンテナはApache-PHPのimageのため、Apacheのアクセスログとlaravelのログが混在すると非常に見にくい事になってしまいます。そこでアクセスログは出力しない設定とし、laravelのログのみを標準出力してCloudWatch Logsに出すようにしています。アクセスログはCloudFrontとELBのログで十分だという判断です。
RDS Aurora MySQL
エンジンのログとスロークエリのログをlog_output = FILEとして保存しています。が!基本的な調査はPerformance Insightが優秀すぎてこちらで十分となっています。
リプレース後のトラブル
リプレース後はまったく問題ありませんでした!!!!
…といって良いくらいトラブルはなかったと言いたいのですが細かなところはトラブルが発生してしまいましたのでご紹介したいと思います。
・セール時のスケールが間に合わない
ECSサービスではスケールアウトトリガーとして平均CPU使用率が50%を超えると2タスク追加、70%を超えると3タスク追加、、、といった設定をしていましたが、セール開催後のスパイクはコンテナの起動速度をもってしても間に合わず、開催後の30秒ほどは繋がるのに時間がかかる状態となってしまいました。負荷テストにてスケールのテストを行わなかった事が敗因です。こちらはスケールのトリガーを平均CPU使用率から過去1分の最大CPU使用率のメトリクスとする事である程度改善されましたが、それでも瞬間的には繋がりにくくなってしまいましたので、あらかじめわかっている大きなセール時はコンテナの最小台数を増やしておく事で問題なく運用できています。(いわゆる「運用でカバー」…)。ちなみにスケールインは平均CPU使用率が25%以下の時に1タスクづつ削除としています。
・高負荷時にメール送信でエラーが発生する
メールはlaravelからSESへ送信していたのですが、Mailファサードのエラーでメール送信が失敗するという問題が発生しました。エラーの内容的に理論上に発生しえないエラーが発生していたり、特定コンテナだけで発生したりといった状況だったのですがやはり原因は不明でMailファサードを捨ててAWS SQSで逃す構成へ変更しました。
これはAWS Dev Day 2022 Japanで登壇されていた株式会社メイツさまの「サーバーレスなメール送信システムをAWS CDKで構築し数千人規模の環境で運用した話」の内容をかなり参考(というかほぼ乗っかり)させていただきました。
サーバーレスでスケールするメール送信システムをAWS CDKで構築する
https://go-to-k.hatenablog.com/entry/mail-queues
非常に詳細な構築面の解説があり、CDKも用意されていて非常に助かりました。この構成は元々石田さんも知っていてPoCしていたようでこちらも非常にスムーズに実装されました。こちらの構成後、メール送信トラブルは起きていません。
終わり
本番へのリプレース作業が完了した後の初回のセールは結構緊張しましたが無事に乗り越え、今の所大きな不具合がなく運営できており、よかったです。
来年も何か「頑張ったなーー」と思えるような事をやれたらと思います。
今年はありがとうございました。来年もよろしくお願いいたします!
