
こんにちは、クラウドソリューション事業部の本田です。今月もブログ書いていきます、よろしくお願いします。今回ですが、担当している案件でRDSのS3エクスポートを自動化する必要がありましたので、それを実現した内容をまとめていきます。
背景
GCPのBigQueryにRDSのデータをインポートする必要がありました。dumpを取得してデータを転送するなど色々と考えたのですが、BigQueryではparquet形式のデータをサポートしているので、RDSのデータをparquet形式でエクスポートすることのできるRDSスナップショットのS3エクスポートを利用することになりました。また週に1回での更新頻度という要件でしたので、こちらを自動化する必要がありました。BigQueryでのテーブルの作成なども行なっているのですが、これらはまた別の記事にしようかなと思っています。
構成
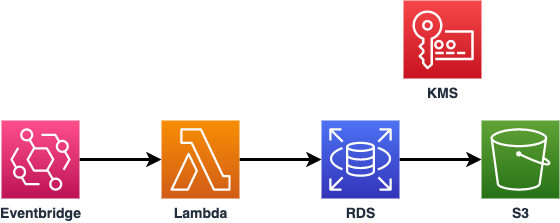
AWS LambdaでRDSスナップショットのS3エクスポート処理を行い、その関数をEventbrigdeで定期実行させるというような構成です。S3へのエクスポートにはKMSを利用が必要となります。弊社の過去のブログで、S3エクスポートについては書かせていただいているので必要なリソース作成についてはこちらもご覧ください。
https://www.seeds-std.co.jp/blog/creators/2020-02-27-183446/
自動化についてですが、一旦コンソール使って実行することをオススメします。というのもIAM Roleなど自動で作成されるものを流用する方が最低限の権限で作成されるので、設定が楽になります。
S3の作成
任意のバケット名でS3を作成します。設定などはデフォルトで問題ありません。
KMSの作成
こちらも任意の名前で作成します。デフォルトの設定で問題ありません。Lambdaを作成後に、Lambdaのロールを作成したキーの所有者に追加して、Lambdaから作成したキーを利用できるようにします。
AWS Lambdaの作成
以下のようなソースコードになります。ランタイムははnode.jsの最新で、arm64で動かしています。csv-parseのモジュールについては別途インストールが必要となります。今回エクスポート対象としているのが、RDSクラスターのスナップショットを対象としています。つまりRDSのAuroraを対象としていますので、MySQLなどクラスターでない場合は、RDSインスタンスを対象として指定する必要があります。
1const AWS = require('aws-sdk');
2const { parse } = require('csv-parse/sync');
3const fs = require('fs');
4
5exports.handler = (e, ctx) => {
6
7 // taskID用に日付を取得
8 // 現在時刻の取得
9 var dt = new Date();
10
11 // 日本の時間に修正
12 dt.setTime(dt.getTime() + 32400000); // 1000 * 60 * 60 * 9(hour)
13 // 日付を数字として取り出す
14 var year = dt.getFullYear();
15 var month = dt.getMonth() + 1;
16 var day = dt.getDate();
17 var hour = dt.getHours();
18 var min = dt.getMinutes();
19 // 値が1桁であれば '0'を追加
20 if (month < 10) {
21 month = '0' + month;
22 }
23 if (day < 10) {
24 day = '0' + day;
25 }
26 if (hour < 10) {
27 hour = '0' + hour;
28 }
29 if (min < 10) {
30 min = '0' + min;
31 }
32 // 出力
33 var today = year + month + day;
34
35 // エクスポート対象テーブルを取得
36 const data = fs.readFileSync('table.csv');
37 const parseData = parse(data);
38
39 const exportTables = parseData.reduce((newArr, elem) => {
40 return newArr.concat(elem);
41 }, []);
42
43 // S3エクスポートを実行
44 const rds = new AWS.RDS();
45 var params = {
46 DBClusterIdentifier: process.env.DBCLUSTER_IDENTIFIER,
47 };
48 console.log(params);
49 rds.describeDBClusterSnapshots(params, function (err, data) {
50 if (err) console.log(err, err.stack); // an error occurred
51 else {
52 const response = data['DBClusterSnapshots'];
53 const latestSnapshot = response.sort(
54 // snapshotを降順で取得
55 (a, b) => (a.SnapshotCreateTime?.getTime() ?? 0 < (b.SnapshotCreateTime?.getTime() ?? 0)) ? -1 : 1
56 )[0];
57 console.log(latestSnapshot);
58 const snapshotArn = latestSnapshot?.DBClusterSnapshotArn;
59 console.log(snapshotArn);
60 const taskID = "export-task" + today ;
61 var params = {
62 ExportTaskIdentifier: taskID, /* required */
63 IamRoleArn: process.env.IAM_ROLE_ARN, /* required */
64 KmsKeyId: process.env.KMS_KEY_ID, /* required */
65 S3BucketName: process.env.S3_BUCKET_NAME, /* required */
66 SourceArn: snapshotArn, /* required */
67 ExportOnly: exportTables, /* テーブルを指定する場合はこちらを利用 */
68 };
69 rds.startExportTask(params, function (err, data) {
70 if (err) console.log(err, err.stack); // an error occurred
71 else console.log(data); // successful response
72 });
73 }
74 });
75}table.csvで、エクスポートしたい対象のテーブル名を指定することで、対象テーブルのみエクスポートすることが可能です。以下のような記載をします。
1データベース名.テーブル名環境変数の設定
以下の環境変数を設定します。
・DBCLUSTER_IDENTIFIER:エクスポート対象にするDBクラスター名
・ IAM_ROLE_ARN:S3エクスポート用のIAM Role
・KMS_KEY_ID:KMSのキーID
・S3_BUCKET_NAME:エクスポート先のS3名
IAM Roleの修正
Lambdaを作成した際に作成されるIAM Roleに以下のポリシーを追加します。
1.exportタスクの実行とスナップショットを取得する権限を追加
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Sid": "VisualEditor0",
6 "Effect": "Allow",
7 "Action": [
8 "rds:StartExportTask",
9 "rds:DescribeDBClusterSnapshots"
10 ],
11 "Resource": "*"
12 }
13 ]
14 }2.exportタスクへのPassRoleする権限を追加
S3エクスポートを利用する際にIAM Roleが作成されますので、Lambdaからそちらの権限をPassRoleできるように設定します。
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Action": "iam:PassRole",
6 "Resource": "arn:aws:iam::account_id:role/service-role/Role_Name",
7 "Effect": "Allow"
8 }
9 ]
10 }KMSの所有者に追加
Lambdaからexport用のKMSキーを利用できるように、所有者にLambdaのIAM Roleを追加します。

IAM Role名はLambda作成時に作成されるものを指定しています。
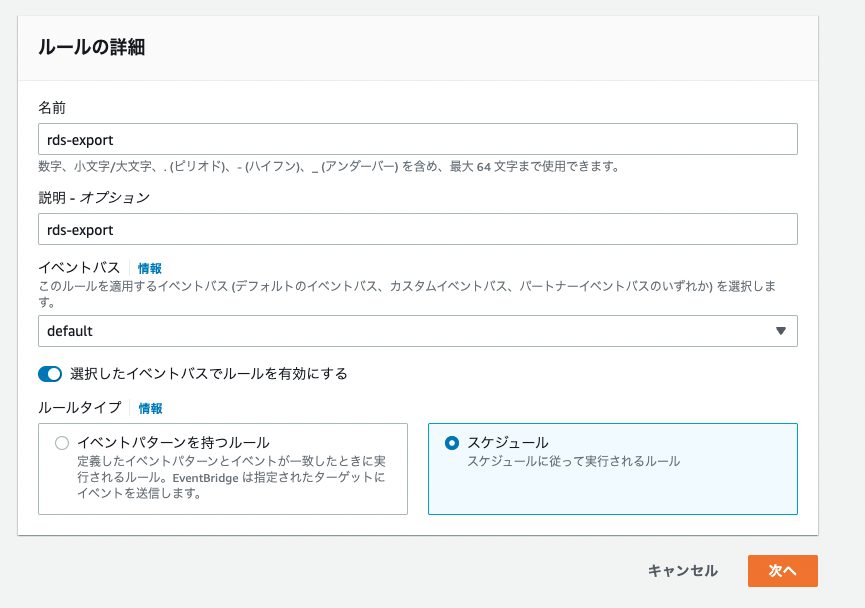
Eventbridgeの作成
Lambdaを作成したので、こちらをEventbrigdeで指定した時間に自動で動かすように設定します。以下のように作成していきます、ルール名は任意で、また関数名は作成したものを指定してください。
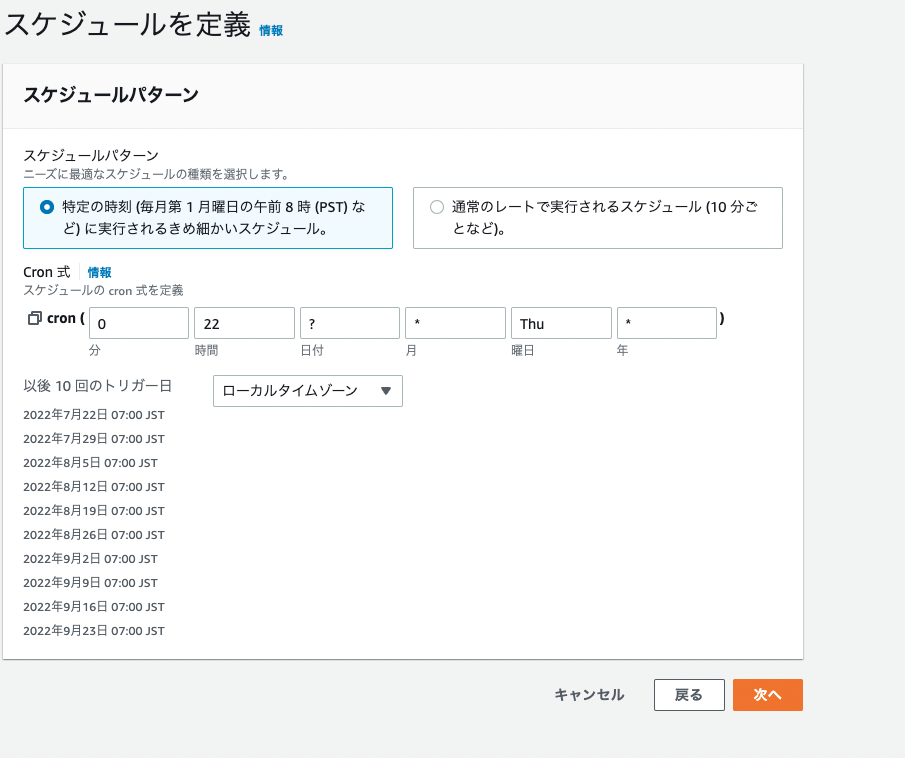
毎週金曜朝の7時に実行する設定です。
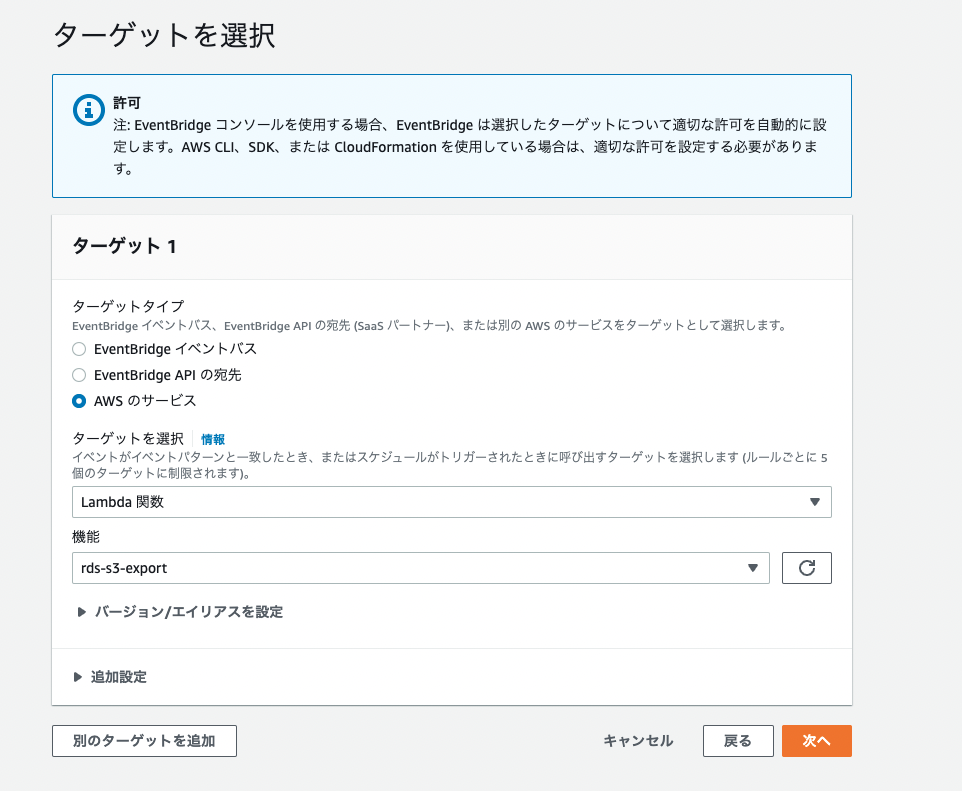
作成したLambda関数を指定します。あとは指定した時間にS3エクスポートが実行されているか確認します。S3にエクスポートされたファイルが溜まっていくので、S3のライフサイクルを設定して定期的に削除やアーカイブしていくのも良いでしょうね。
最後に
エクスポートを完了したことをEventbrigdeなどで取れるかなと色々と探していたのですが、現時点では見つけられずでした。AWS CLIを使ってエクスポートタスクの状況を確認することもできるのでCodebuildなどであればタスクの状況を定期的に確認して、終了次第に次の処理を実行ということができそうです。ただこのエクスポート処理自体が対象のデータベースによりますが、結構時間がかかったりするので、コスト面を考えるとLambdaでタスクの開始だけを行うというのが良いと思います。またエクスポートが完了するとS3バケットにファイルが出力されるので、S3イベントでそちらを受け取り終了の判定を行うというので問題ないかと思っています。BigQueryへの転送編はまた時間を見て書きたいと思います。
