

CTO の原口です。
2026/04/08 時点で、前日 2026/04/07 に Amazon S3 Files が GA となりました。
これまでにも Mountpoint for S3、AWS Storage Gateway、s3fs、goofys など、S3 をファイルシステム的に扱う仕組みはいくつかありましたが、それらと比べて何が違うのか、そして POSIX ベースの共有ストレージである Amazon EFS とどう棲み分けられるのかが気になったので、触って調べてみました。
Amazon S3 Filesとは
ざっくり言えば、S3 を正本にしたまま、Linux ベースのコンピュートから NFS インターフェース経由で共有ファイルシステムのように扱えるサービスです。Amazon EFS をベースにした ハイパフォーマンスストレージ を用いて ファイルシステムビュー を提供しつつ、S3 と自動同期するのが特徴です。
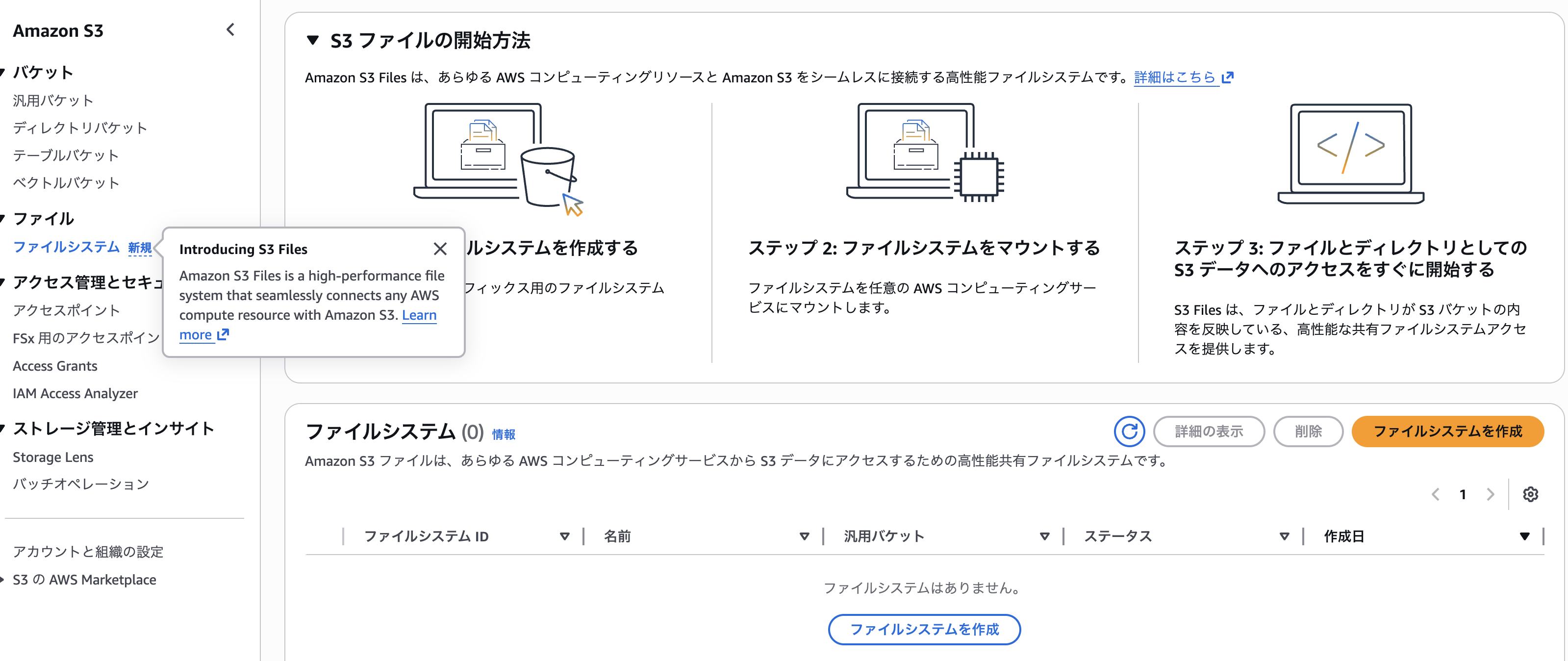
S3のメニューに「ファイルシステム」というのが増えてる
内部仕様
Andy Warfield氏 (S3 Files and the changing face of S3) のブログに詳細が書かれているので要約します
- S3 bucket / prefix を mount対象にできる。
- Andy Warfield 氏の設計解説によれば、mount時、裏側で EFS namespace にS3メタデータを展開する。
- アプリからは NFS系ファイルシステムとして見える。
- 小さいファイル(128KB未満)は初回取り込み時にデータ本体も同期する。
- 大きいファイルは メタデータだけ先に取り込み、実データは読まれた時にS3から取得する。
- 書き込みはまずファイル層で受け、stage and commit方式で後からS3へ反映する。
- 変更は 約60秒ごとにまとめてS3へPUTされる。
- S3側で更新されたオブジェクトも、逆方向同期でファイルビューへ反映される。
- 競合時は S3がsource of truth で、ファイル側の競合内容は lost+found に退避される。
- 競合や同期遅延は、CloudWatch メトリクスなどを通じて観測できる
- 長期間アクセスされないファイルデータは、デフォルトでは30日でハイパフォーマンスストレージからexpireされるが、S3上の本体は消えない。
- 連続大容量読み込みでは、NFS経由ではなく S3へ直接並列GETする read bypass が使われる。
- ディレクトリrenameは、S3にrenameがないため copy + delete相当 で高コストになりうる。
- POSIXファイル名にできないS3キーはファイルビューに載らない。
- 完全にファイルとオブジェクトを同一化するのではなく、両者の境界を明示した同期モデルを採っている。
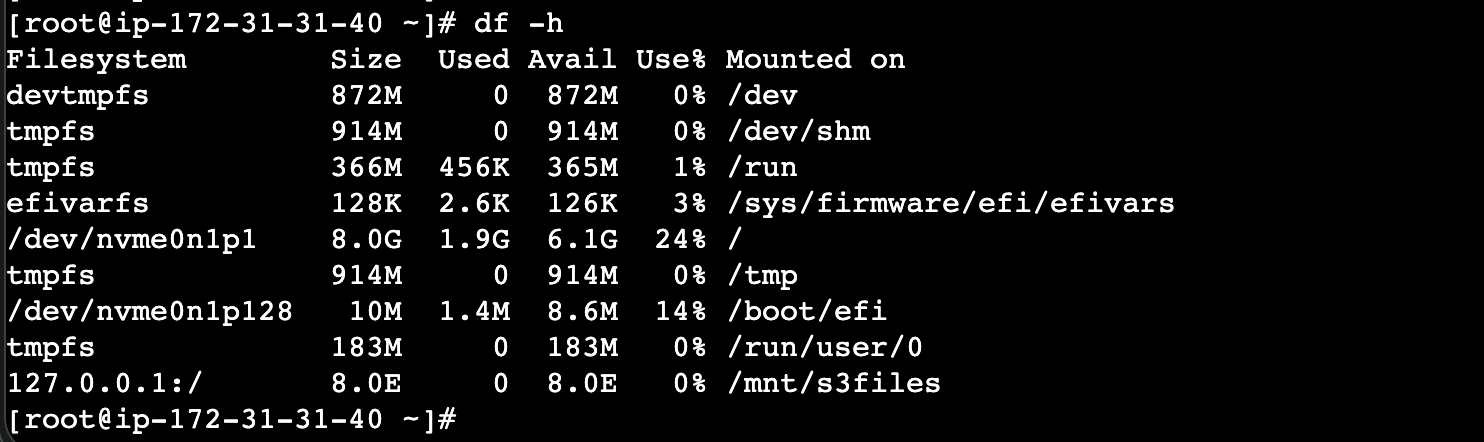
マウントしたら8.0E となっていました。
Stage and Commitという考え方が最重要ポイントかな、と考えていてファイルシステムとオブジェクトという異なるストレージの両者をマージするのではなく、逆に明示的な境界を作る設計に振り切っているのが素敵ですね。
POSIX属性
パーミッションやGID/UIDなどの取扱については以下ドキュメントに記載がありました
https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-files-synchronization.html
- S3 Files はファイルシステムビュー上では POSIX permissions を提供する
- UID/GID やパーミッション は S3 オブジェクトのメタデータに永続化される
- 再マウント時や再インポート時にメタデータが再適用される
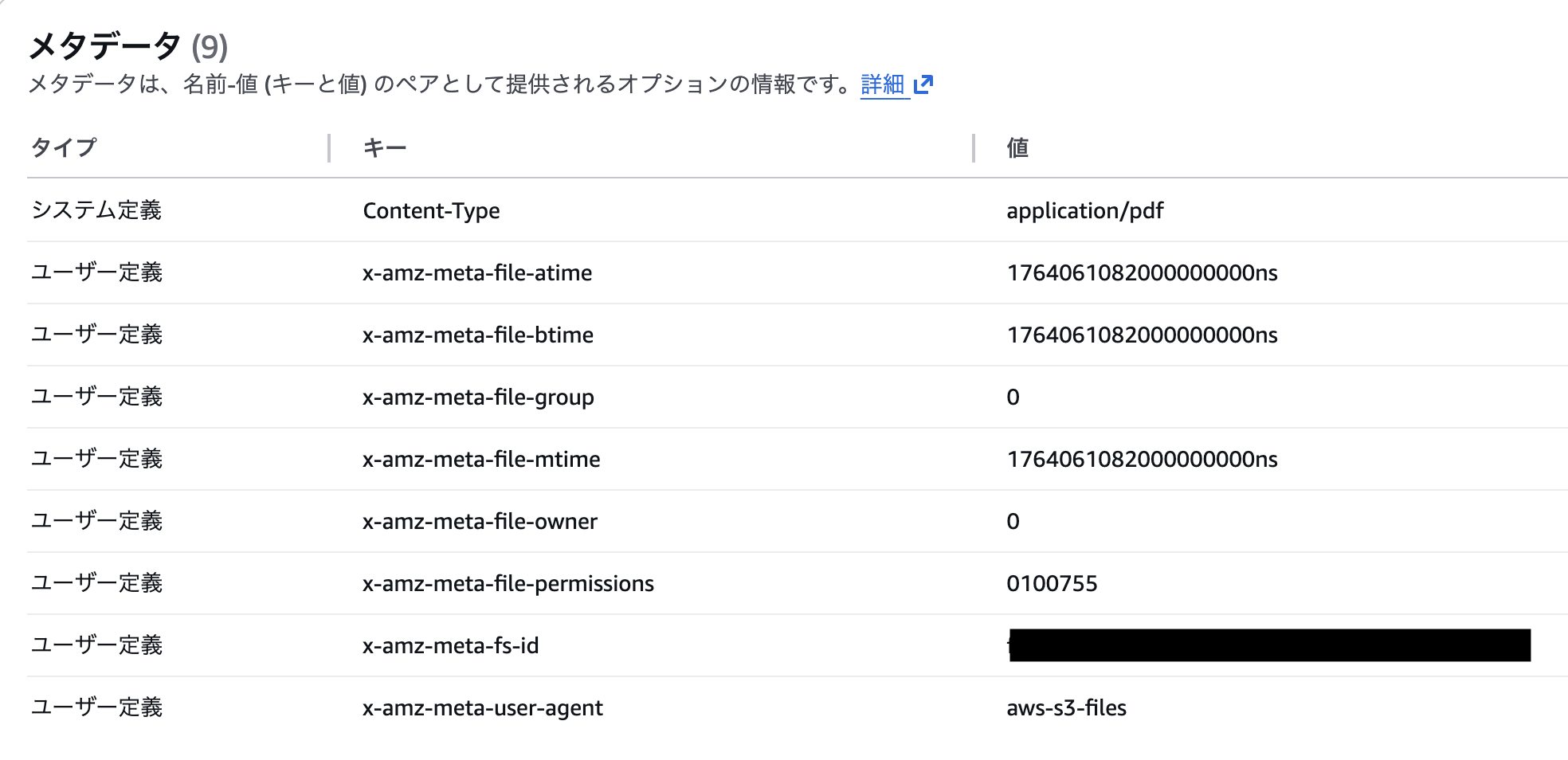
試しにパーミッションを755に変えてみたら、きちんとオブジェクトのメタデータへ保存されていました
コスト
Amazon EFSを使った場合はコストが高くなるので、S3 Filesの場合にコストが削減できるのかどうかを考えてみます。
Amazon S3 Filesのコストは
- 通常のS3への保管料金
- S3 Files 側の ハイパフォーマンスストレージに保持されるデータの料金
- S3 Filesからの data / metadata access 料金
- 同期や大容量読み取りに伴って発生する S3 の GET / PUT / LIST などの料金
ただ、S3 Files では、「同期の設定」 により、どのデータをハイパフォーマンスストレージに取り込むか、また未使用データをどのくらいの期間保持するかを調整できます。
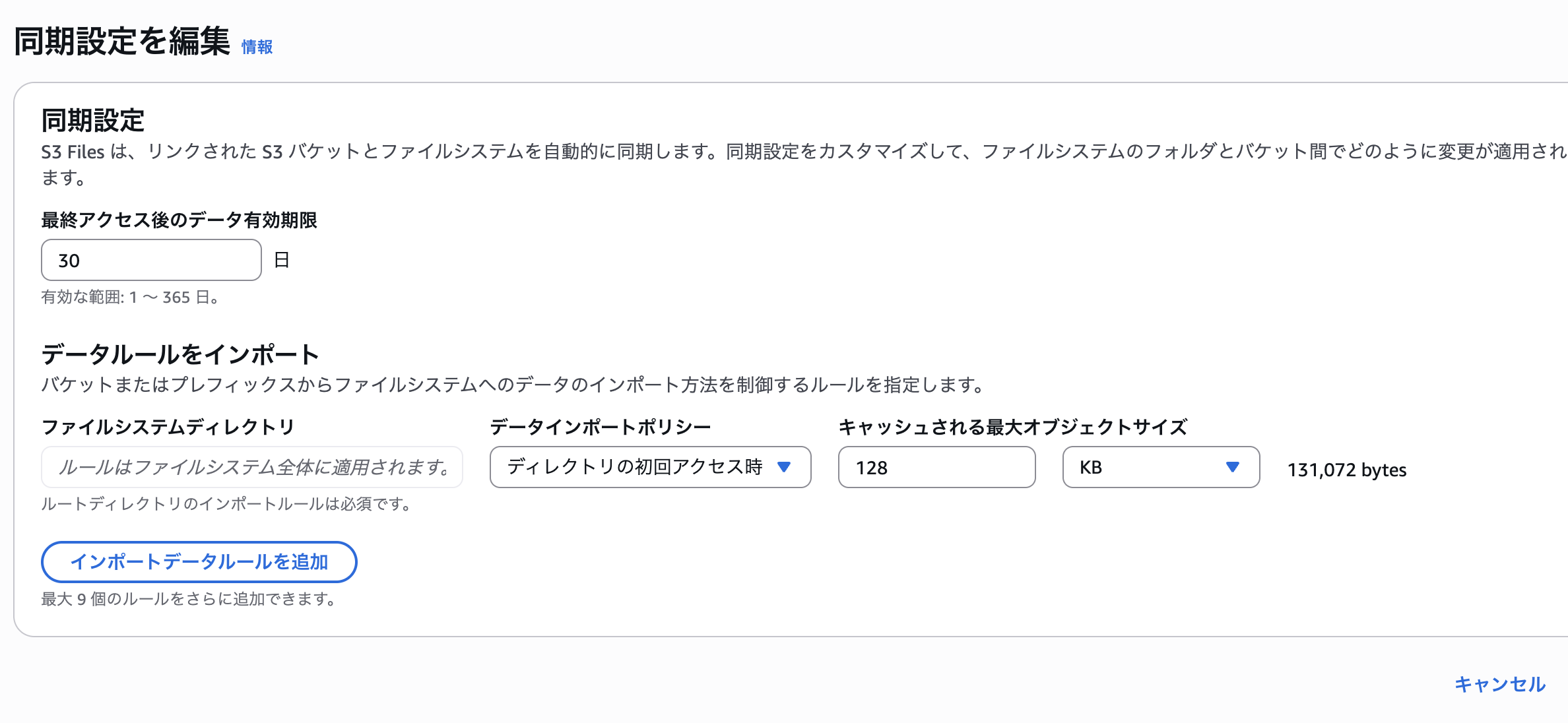
S3 に本体を置いたまま、ホットデータだけハイパフォーマンスストレージに乗せるような形にすることで、素のAmazon EFS利用よりもコストが抑えられそうな場合も考えられ、その際はAmazon S3 Filesは大きな候補となるかもしれません。
ユースケース
たとえば大容量のAI モデルをS3 に保存しつつ、学習・推論環境からはファイルシステムとして扱いたいケースでは、S3 を正本に保ちながらファイルアクセスの利便性を得られます。特に大きなシーケンシャル読み取りでは read bypass によりS3 から直接読み出されるため、利便性とコストのバランスが取りやすいユースケースのひとつかもしれません。
まとめ
通常の共有ファイルストレージが欲しいだけで、正本を S3 に置く明確な理由がないなら、まずは Amazon EFS を検討するのが自然です。
しかし
- データの正本がS3にあって欲しい
- ユースケースによってEFSを利用するよりコストが下げれそう
というケースではS3 Filesは有力候補となりそうです。