

こんにちは。クラウドソリューション事業部の石垣です。
Amazon DynamoDB(以下、DynamoDBと表記します)にCSVファイルからテストデータをインポートしたい時に使えそうなツールを見つけましたのでご紹介します。
csv-to-dynamodbの紹介
今回使用したのは、aws-samplesのcsv-to-dynamodbとなります。aws-samplesはAWS公式で用意されているサンプル集となります。今回ご紹介するもの以外にもいろいろ興味深いものがありますので、暇を見つけていろいろ見たり触ったりしたいです。
csv-to-dynamodbのソースコードは以下となります。
https://github.com/aws-samples/csv-to-dynamodb
使い方は、readmeに記載してますし、以下のブログでも説明があります。
この記事は、Amazon DynamoDB へのデータの取り込みに今日どのようなソリューションが存在するかを再 […]

CloudFormationテンプレートを実行する形となりますが、デプロイされるコンポーネントとしては以下の通りです。

使用イメージは以下のような感じとなります。
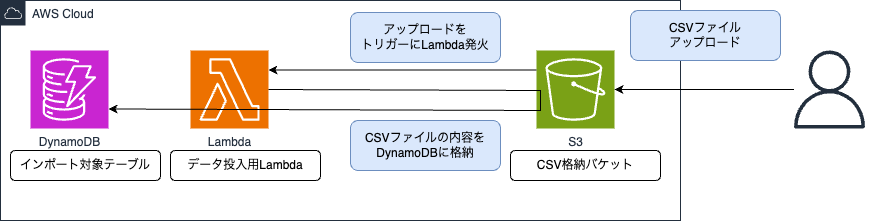
デプロイしてみる
では、さっそく作っていきましょう。
githubリポジトリのcloudformation/CSVToDynamo.templateをアップロード。
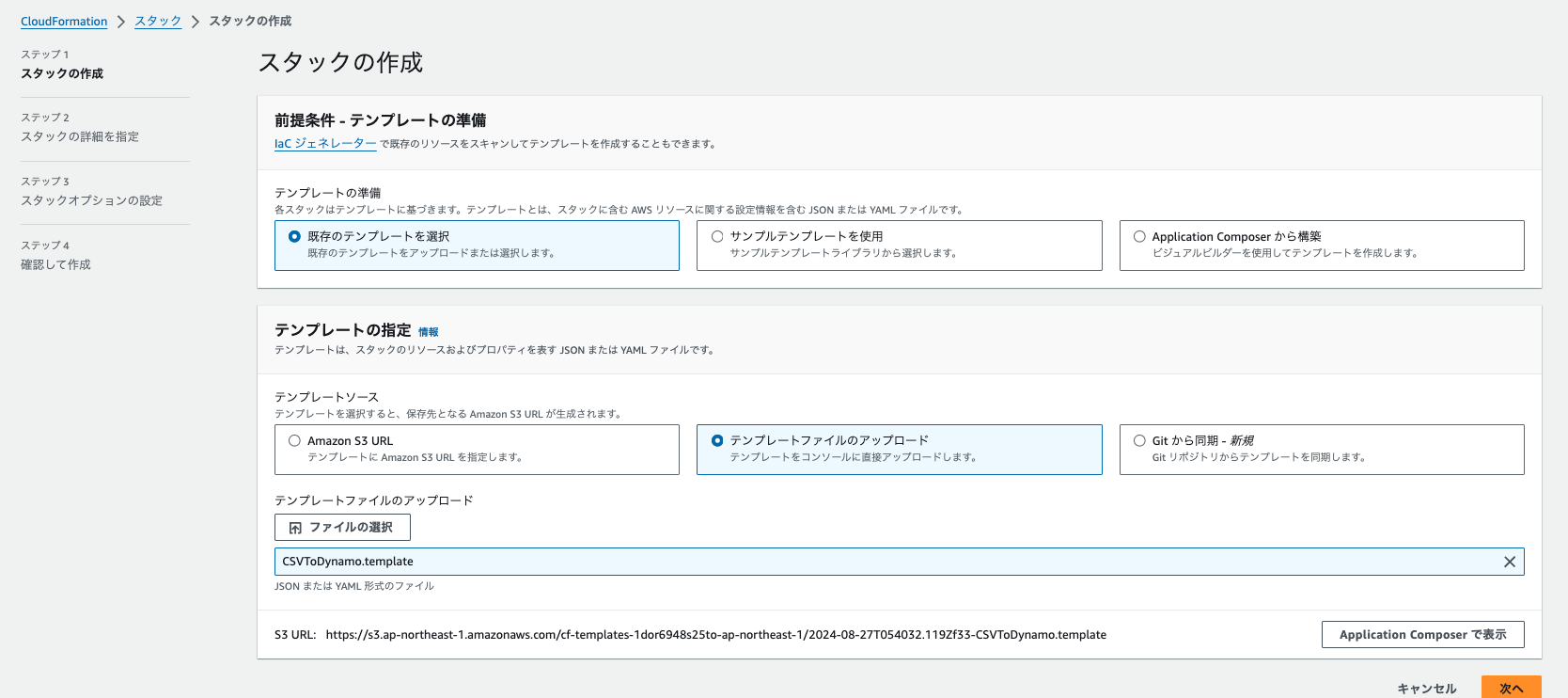
バケット名、DynamoDBテーブル名、CSVファイル名を入力して次へ。
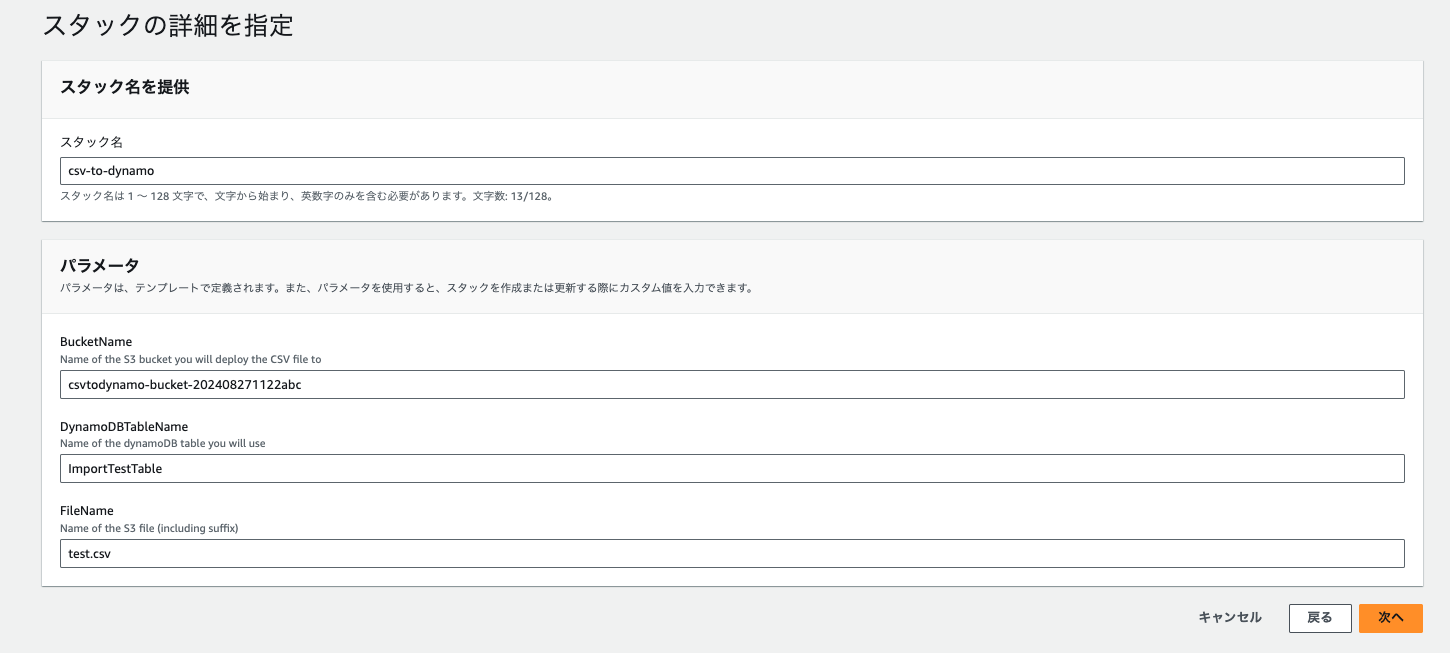
スタックポリシーはお好みで、スタック作成。ポチッ。
エラーになります…
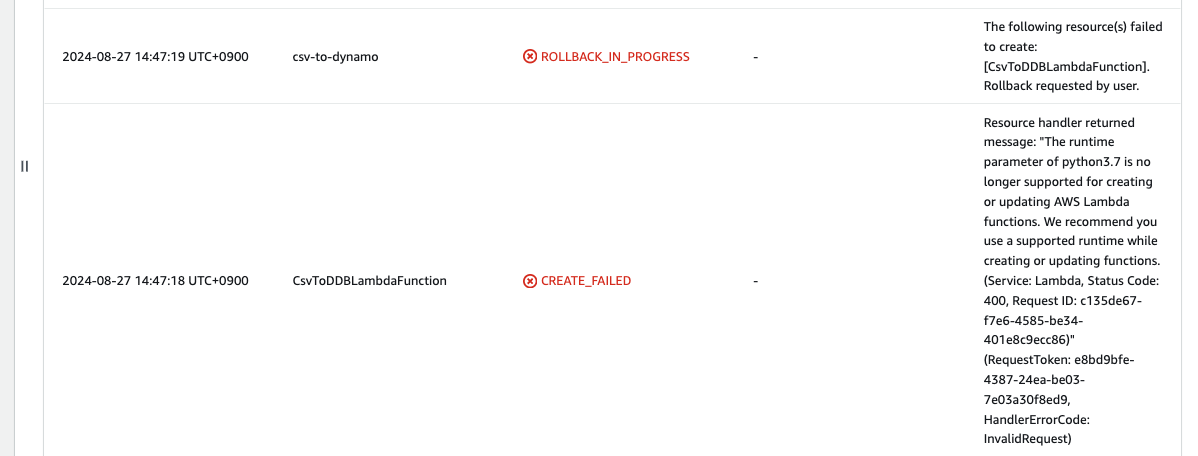
テンプレートファイルの中で作成しようとしているLambda関数のランタイムがPython3.7であることが原因です。
テンプレートファイル内のLambdaランタイムバージョンを3.7→3.12に変更してリトライします。
無事デプロイされました。
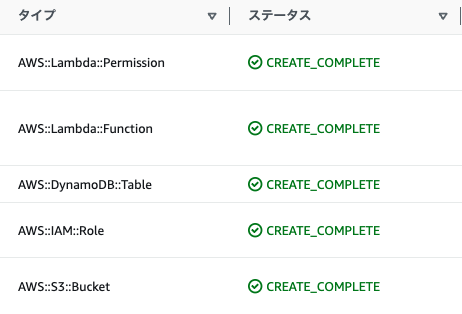
動かしてみる
さっそく動かしてみましょう。
S3バケットに指定したファイル名でcsvファイルをアップロードします。

DynamoDBを確認すると…
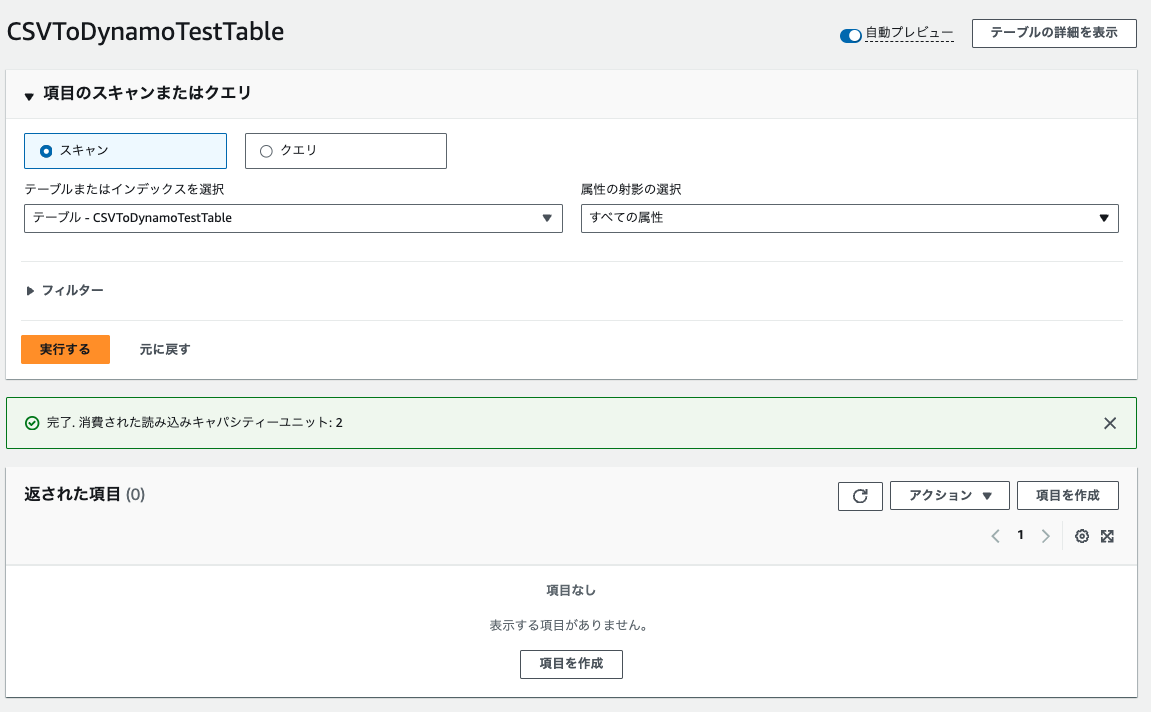
何もデータが入ってませんね。
Lambdaのほうを確認します。
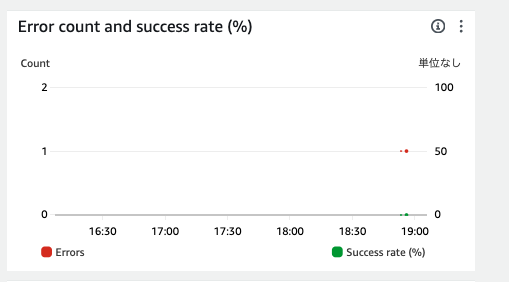
なにかエラーが発生していたようで、ログを確認します。
1[ERROR] Runtime.UserCodeSyntaxError: Syntax error in module 'index': unindent does not match any outer indentation level (index.py, line 55)
2Traceback (most recent call last):
3 File "/var/task/index.py" Line 55
4 print("Error loading DynamoDB table. Check if table was created correctly and environment variable.")なにかインデントがおかしいとのこと。
コードを確認するとたしかにインデントがなにかおかしいですね。
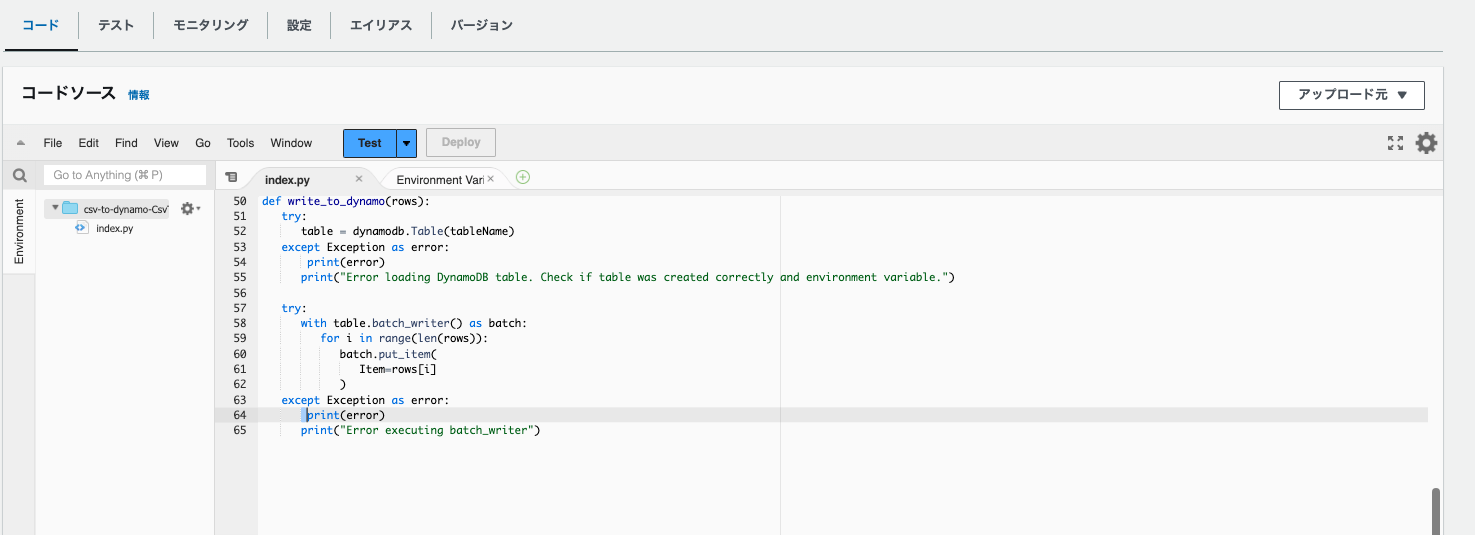
よく見たらgithubリポジトリのほうでも関連のPRが起票されてました。
https://github.com/aws-samples/csv-to-dynamodb/pull/15
ということで該当の箇所を修正してリトライ。
うまくいきました。
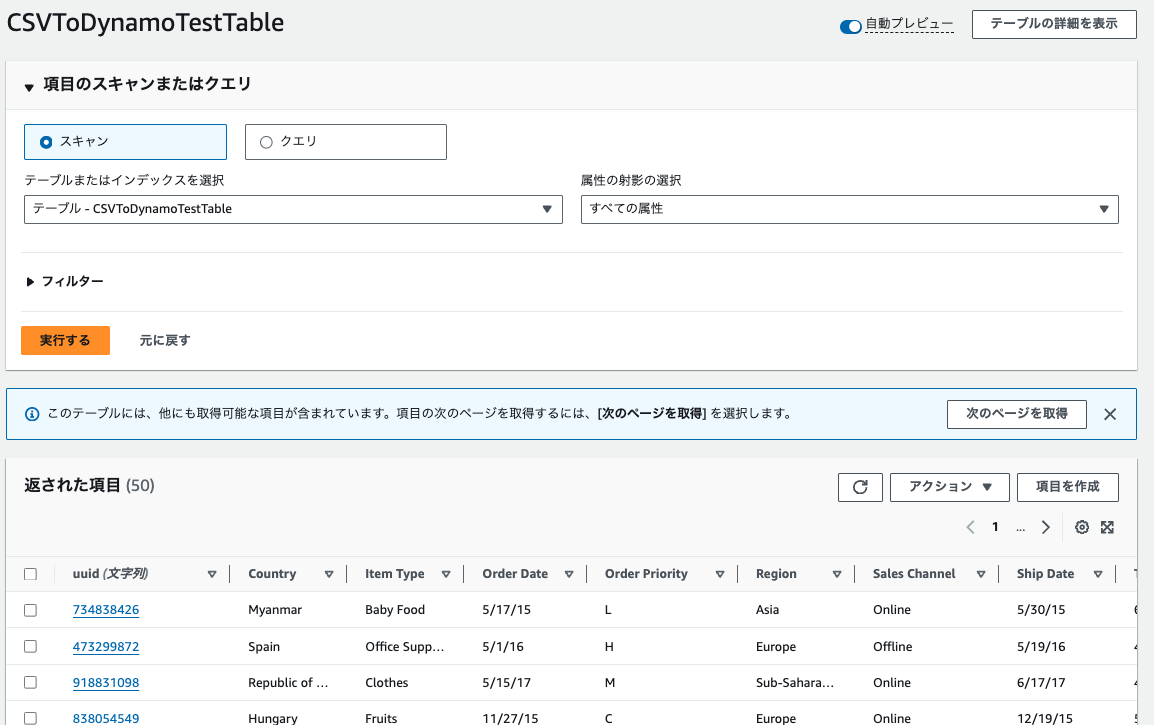
中のデータを見てみると、すべてStringになっていますね。
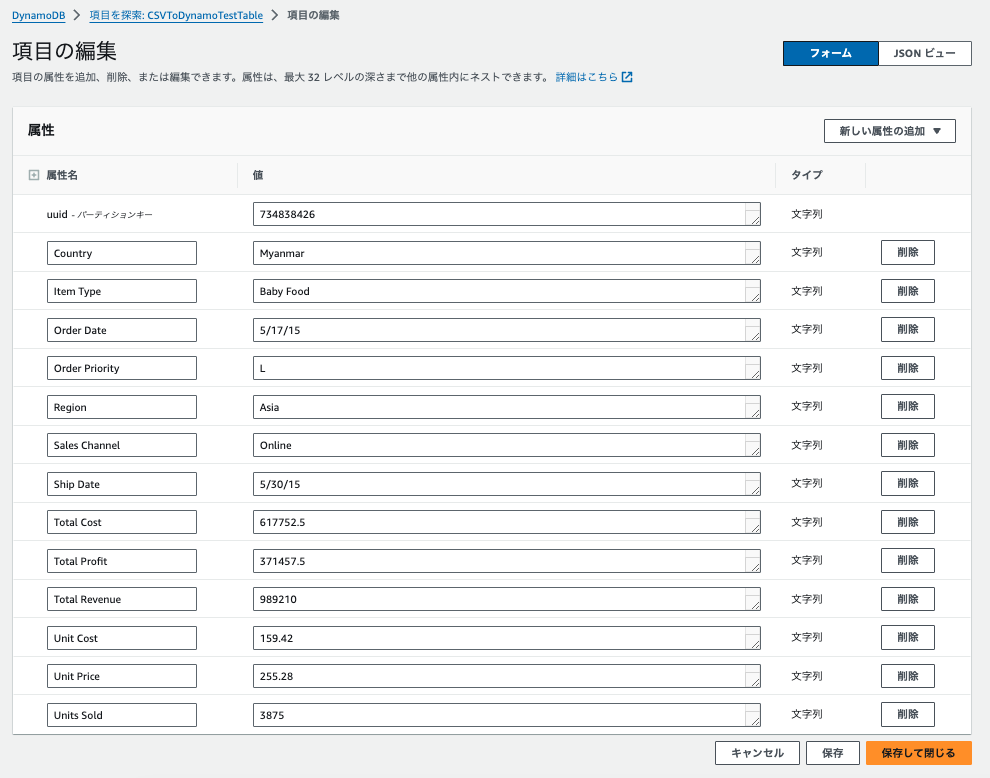
Stringでも問題ないようなテストデータなら、ここまでで十分使用できそうです。
String以外のAttribution Typeでインポートしたい時
タイプ(Attribution Type)を指定のものにしたい時はもう一手間加える必要がありそうです。
そもそもなぜ、すべて文字列になっているかというと、サンプルのLambda関数の中でcsv.DictReader を使用してCSVを読み込んでいますが、その仕様ですべて文字列となっているからとなります。
なので、読み込んだ後で個別に変換をかけてあげればいいです。
例えば以下のような形。(enabled列をbool型に変換の例)
1def convert_row(row):
2 row['enabled'] = bool(row['enabled'])
3 return row上記を以下のような具合に、CSV読み込みの後で呼べばいいです。
1前略
2
3 #DictReader is a generator; not stored in memory
4 for row in csv.DictReader(codecs.getreader('utf-8-sig')(obj)):
5 row = convert_row(row)
6 if len(batch) >= batch_size:
7 write_to_dynamo(batch)
8 batch.clear()
9
10 batch.append(row)
11
12後略これで再度CSV格納すると、以下のような具合で狙ったAttribution Typeでデータが格納されました。
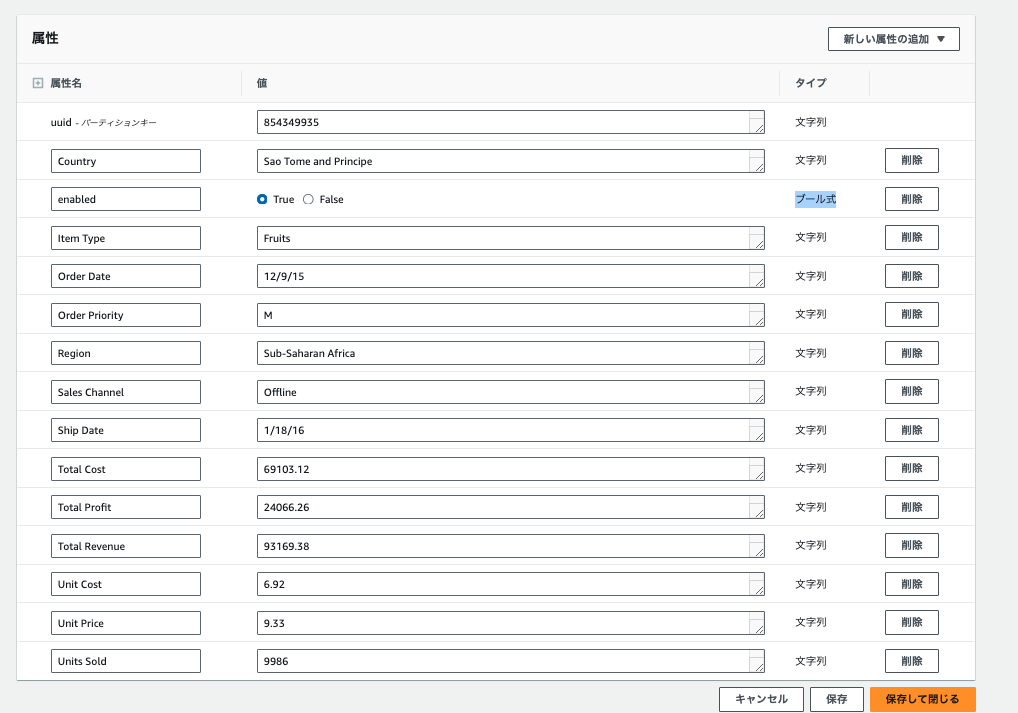
全体のコードしては以下のような具合です。(convert_rowの中はCSVファイルの内容にあわせて適宜で要調整)
1import json
2import boto3
3import os
4import csv
5import codecs
6import sys
7
8s3 = boto3.resource('s3')
9dynamodb = boto3.resource('dynamodb')
10
11bucket = os.environ['bucket']
12key = os.environ['key']
13tableName = os.environ['table']
14
15def lambda_handler(event, context):
16
17
18 #get() does not store in memory
19 try:
20 obj = s3.Object(bucket, key).get()['Body']
21 except Exception as error:
22 print(error)
23 print("S3 Object could not be opened. Check environment variable. ")
24 try:
25 table = dynamodb.Table(tableName)
26 except Exception as error:
27 print(error)
28 print("Error loading DynamoDB table. Check if table was created correctly and environment variable.")
29
30 batch_size = 100
31 batch = []
32
33 #DictReader is a generator; not stored in memory
34 for row in csv.DictReader(codecs.getreader('utf-8-sig')(obj)):
35 row = convert_row(row)
36 if len(batch) >= batch_size:
37 write_to_dynamo(batch)
38 batch.clear()
39
40 batch.append(row)
41
42 if batch:
43 write_to_dynamo(batch)
44
45 return {
46 'statusCode': 200,
47 'body': json.dumps('Uploaded to DynamoDB Table')
48 }
49
50def convert_row(row):
51 row['enabled'] = bool(row['enabled'])
52 return row
53
54def write_to_dynamo(rows):
55 try:
56 table = dynamodb.Table(tableName)
57 except Exception as error:
58 print(error)
59 print("Error loading DynamoDB table. Check if table was created correctly and environment variable.")
60
61 try:
62 with table.batch_writer() as batch:
63 for i in range(len(rows)):
64 batch.put_item(
65 Item=rows[i]
66 )
67 except Exception as error:
68 print(error)
69 print("Error executing batch_writer")感想など
手元のCSVをDynamoDBにインポートしてテストしたいというケースはままあるので、その際とかに使っていけそうです。タイプの指定もそれほど苦もなくできるのがよさげですね。
