

こんにちは、クラウドソリューション事業部の中村です。
AWS re:Invent 2025で発表されたAmazon Bedrock の Reinforcement Fine-tuning(RFT)について紹介します。

AWS re:Invent 2025 - Keynote with Dr. Swami Sivasubramanian
キーノートで no PhD required と言われていた通り、Reinforcement Fine-tuningが簡単にできるようです。
本記事では、弊社CTO 原口の2025年のslackの発言を元に学習させたモデルを作成してみました。
Reinforcement Fine-tuning(RFT)とは
評価スコアに基づいてモデルを最適化するトレーニング手法です。
従来のファインチューニングでは、教師データを与えて学習していましたが、RFTでは以下の流れで訓練が進みます。
- ベースモデルが出力を生成
- 生成物を報酬関数で評価
- 評価スコアを最大化するようにモデルを更新
Amazon Bedrock の Reinforcement Fine-tuning では、報酬関数に、Model as judgeとCustom codeを利用できます。
Model as Judge
評価基準をプロンプトとして記述しスコアを出力させる方式です。
タスクに応じて、サンプルが用意されています。
Custom Code
AWS Lambdaに評価ロジックを実装し、数値スコアを返す方式です。
独自ロジックを組み込むことが可能になります。
こちらもサンプルコードが用意されています。
構築していく
カスタムモデル完成までの流れ
- 特徴量抽出
- 報酬関数の作成
- デプロイ・動作確認
- 訓練フェーズ
- カスタムモデルのデプロイ
特徴量抽出
Slackにおける 2025年の原口の発言を抽出し、Stylometry(スタイロメトリー)という手法を用いて文章の特徴量を抽出しました。
発言に対して形態素解析を行い、品詞ごとに使用頻度の高い単語(Top Vocab)を集計し、style_profile.jsonに保存します。
Top Vocabを確認すると、業務やAWSに関する単語に混ざって、なぜかござるが含まれていました。
江戸っ子なのかもしれませんw
報酬関数の作成
ここが一番の肝となります。
先ほど作成したstyle_profile.jsonに基づくシンプルな報酬関数を実装しました。
報酬関数内では次の処理を行っています。
- 入力テキストを形態素解析
- style_profile.jsonを用いて特徴量を比較
- スタイルの一致度を評価スコアとして返却
報酬ロジックが完成すれば、RFTジョブから渡されるペイロードを受け取り、対応する評価スコアを返却するだけです。
ペイロードには生成タスクのIDとユーザー、アシスタントのメッセージ履歴が含まれます。
1[
2 {
3 "id": "123",
4 "messages": [
5 {
6 "role": "user",
7 "content": "Do you have a dedicated security team?"
8 },
9 {
10 "role": "assistant",
11 "content": "As an AI developed by Amazon, I do not have a dedicated security team..."
12 }
13 ]
14 }
15]上記の入力に対してスタイルの一致度を数値化し、以下の形式で評価結果を返却します。
1[
2 {
3 "id": "123",
4 "aggregate_reward_score": 0.85
5 }
6]Reinforcement fine-tuning (RFT) for Amazon Nova models
デプロイ・動作確認
報酬関数をLambdaにデプロイし、ランダムに選択したデータでテストした結果です。
| author | message | score |
| 原口① | ただログを見る感じ素振りの… | 0.4637017664827 |
| 原口② | Switch2、明後日発売とか信じられない | 0.5649651859043 |
| 原口③ | あわわ、、、結構年末の新NISA枠調整のために… | 0.6182838752809 |
| 中村① | そちらの日時でよろしくお願いします!水曜なので出社します! | 0.43217196818140 |
| 中村② | ですです!S3はアカウント内じゃなくて… | 0.64310761962242 |
| 中村③ | 直アクセスはできるけど、トップに表示されてなさそ | 0.35186581915981 |
原口の発言は概ね高いスコアとなっていますが、スコアの分布が近く、報酬としての分離度が十分でないので、重みづけを追加します。
| author | message | score |
| 原口① | ただログを見る感じ素振りの… | 0.71123323313863 |
| 原口② | Switch2、明後日発売とか信じられない | 0.6972647064859 |
| 原口③ | あわわ、、、結構年末の新NISA枠調整のために… | 0.7778467356159 |
| 中村① | そちらの日時でよろしくお願いします!水曜なので出社します! | 0.3712964592881 |
| 中村② | ですです!S3はアカウント内じゃなくて… | 0.7869817732673 |
| 中村③ | 直アクセスはできるけど、トップに表示されてなさそ | 0.32272924011703 |
本来であれば、教師なし学習などを用いて、重みづけの値自体も最適化するのが望ましいですが、今回は手動で重みを調整しています。
具体的には、以下の特徴量の重みを増加させました。
- 文章の長さ
- 名詞の Top Vocab

重みづけを追加した結果、スコア差が拡大しました。
次に、訓練で使用するプロンプトをjsonl形式で作成します。
訓練用データは最低100件必要なので、手動で作成したプロンプトに加えて、一部はAIを用いてデータを水増ししました。
1{"messages":[{"role":"user","content":"Do you have a dedicated security team?"}]}Requirements for training data sources
訓練フェーズ
リージョンをus-east-1に変更し、Amazon Bedrockのコンソールにアクセスします。

対象のモデルの選択や入力する訓練データ、報酬関数などを設定していきます。
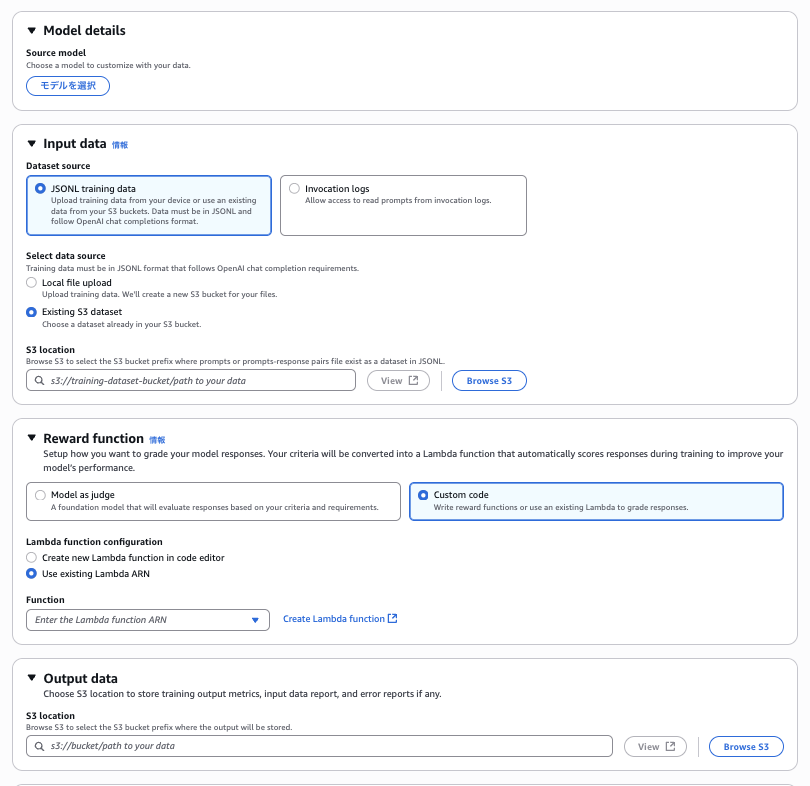
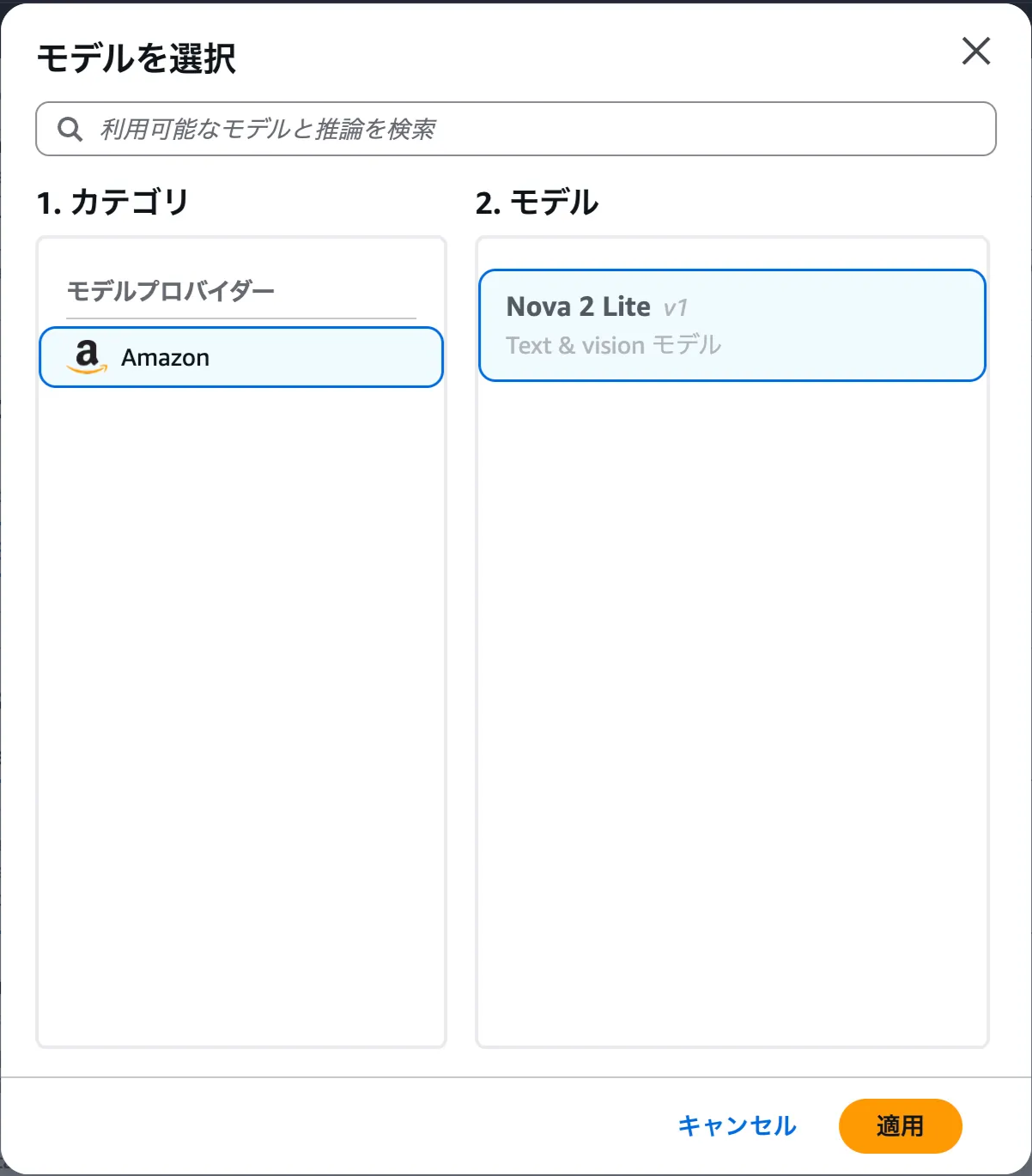
2025/12/30現在は、Nova 2 Liteのみ対応しています。
Create を押下するとジョブを実行するIAMロールがS3やLambdaにアクセスできるかバリデーションが行われます。

ジョブの作成が完了しました。ジョブの完了まで2時間から24時間かかるようです。(ハイパーパラメーター次第かと思われます)

一定時間経過後、学習曲線が表示されました。
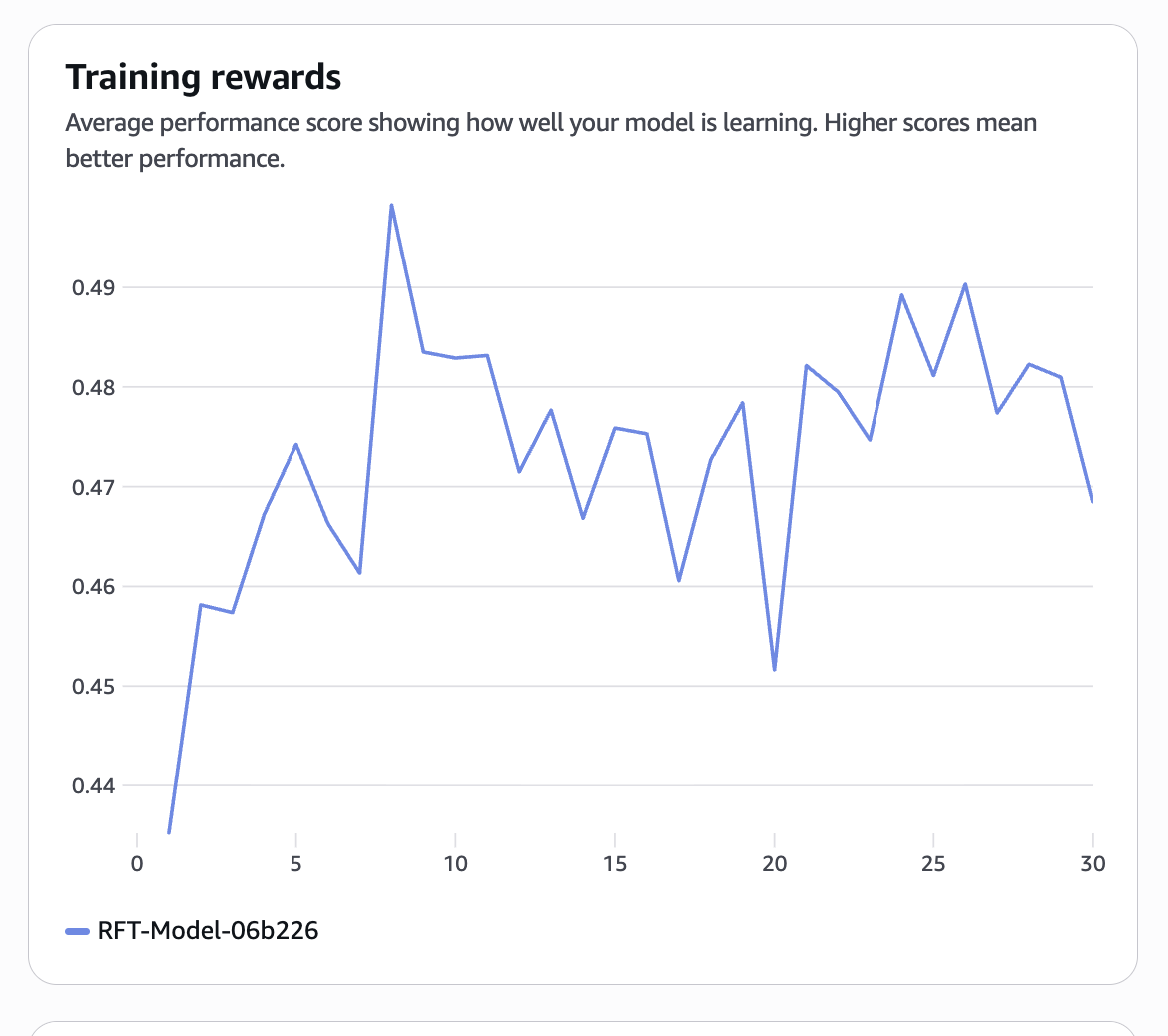
報酬は上昇傾向にあるものの、勾配が小さく、モデルに与えられる報酬シグナルが弱いことが原因として考えられます。

訓練は2時間58分で完了しました。
カスタムモデルのデプロイ
ジョブの完了後、モデルのデプロイを行うことで呼び出しが可能になります。
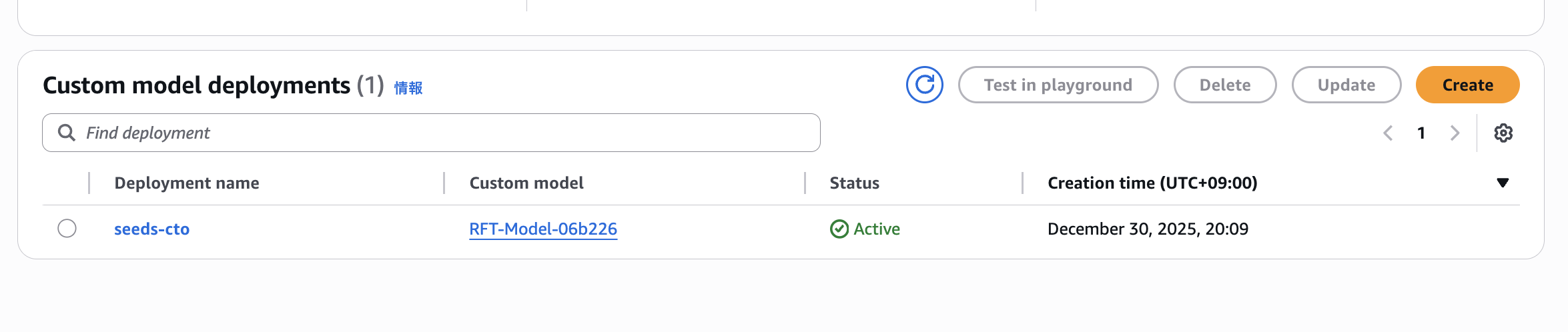
動作確認
学習前のNova 2 LiteとRFT後のNova 2 Liteで比較します。
- 技術系のトピック

- 金融系のトピック
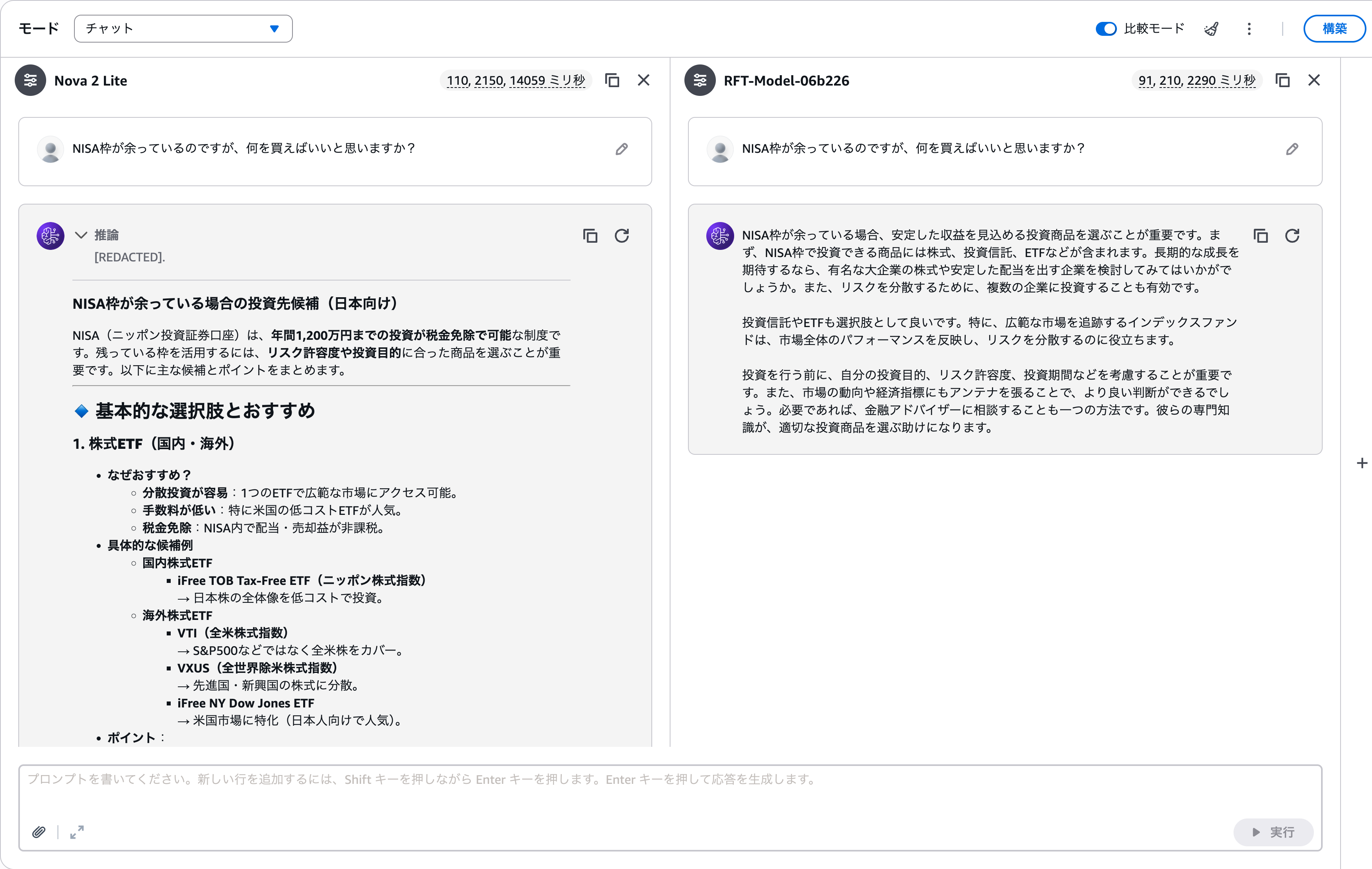
学習後の文章を読んでみると、「なんとなく原口さんっぽいな」と感じる出力が返ってきました。
結論を先に出したり、代替案を添えたりする点に、訓練で獲得した効果が出ていそうです。
コスト
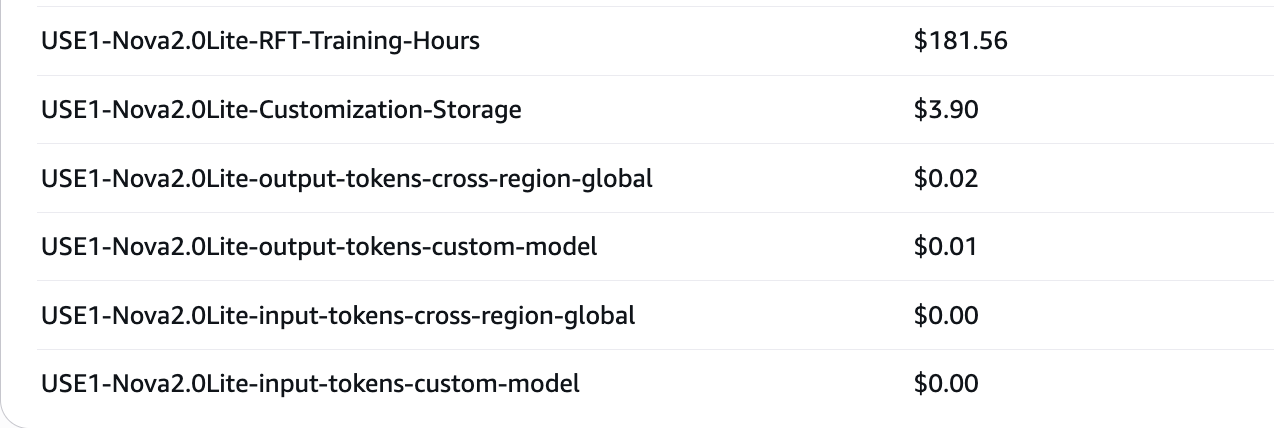
おそらく皆さん気になっていると思います、2025/12/30時点ではドキュメント上でコストの記述が見当たりません。
今回のジョブは2時間58分実行し、合計181.56$となりました。
1分あたり約 1.02$となります。
まとめ
Amazon Bedrock の Reinforcement Fine-tuning(RFT)を「no PhD required」という言葉通り、手軽に試すことができました。
学習曲線を見る限りでは、緩やかな改善にとどまっていましたが、いざモデルの生成結果を確認すると、想定以上にいい出力が得られました。
強化学習という性質上、結果の良し悪しを大きく左右するのはやはり報酬関数の設計だと感じました。本記事ではStylometryを用いましたが、もっと素直にルールベースやアルゴリズムを用いた評価を組み合わせることでより良い訓練ができそうです。
